mirror of
https://github.com/Bunsly/HomeHarvest.git
synced 2026-03-05 03:54:29 -08:00
Compare commits
15 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
c2f01df1ad | ||
|
|
9b61a89c77 | ||
|
|
7065f8a0d4 | ||
|
|
d88f781b47 | ||
|
|
282064d8be | ||
|
|
3a5066466b | ||
|
|
a8926915b6 | ||
|
|
f0c332128e | ||
|
|
2326d8cee9 | ||
|
|
c7a0d6d398 | ||
|
|
940b663011 | ||
|
|
a6fe0d2675 | ||
|
|
3a0e91b876 | ||
|
|
4e6e144617 | ||
|
|
21b6ba44f4 |
216
README.md
216
README.md
@@ -7,9 +7,13 @@
|
||||
|
||||
## HomeHarvest Features
|
||||
|
||||
- **Source**: Fetches properties directly from **Realtor.com**.
|
||||
- **Data Format**: Structures data to resemble MLS listings.
|
||||
- **Export Flexibility**: Options to save as either CSV or Excel.
|
||||
- **Source**: Fetches properties directly from **Realtor.com**
|
||||
- **Data Format**: Structures data to resemble MLS listings
|
||||
- **Export Options**: Save as CSV, Excel, or return as Pandas/Pydantic/Raw
|
||||
- **Flexible Filtering**: Filter by beds, baths, price, sqft, lot size, year built
|
||||
- **Time-Based Queries**: Search by hours, days, or specific date ranges
|
||||
- **Multiple Listing Types**: Query for_sale, for_rent, sold, pending, or all at once
|
||||
- **Sorting**: Sort results by price, date, size, or last update
|
||||
|
||||
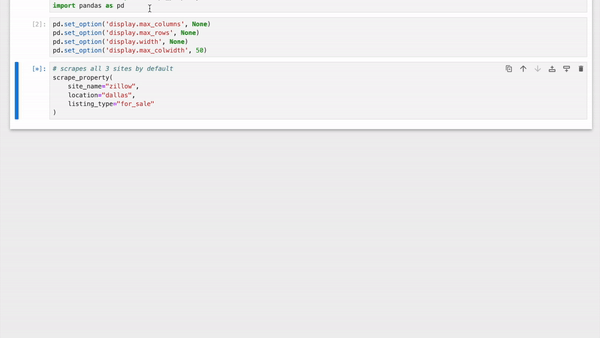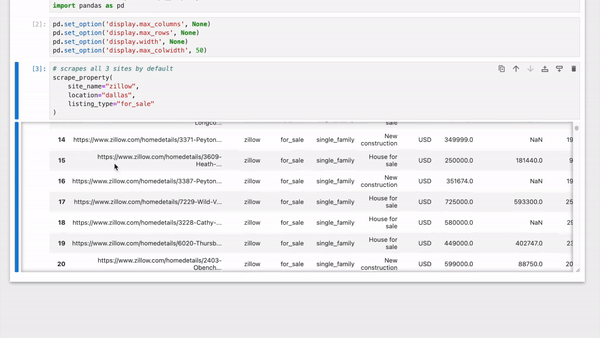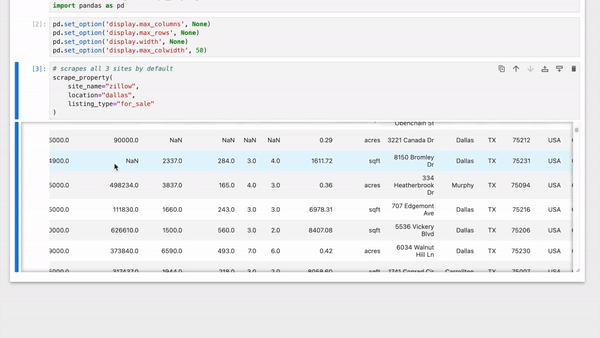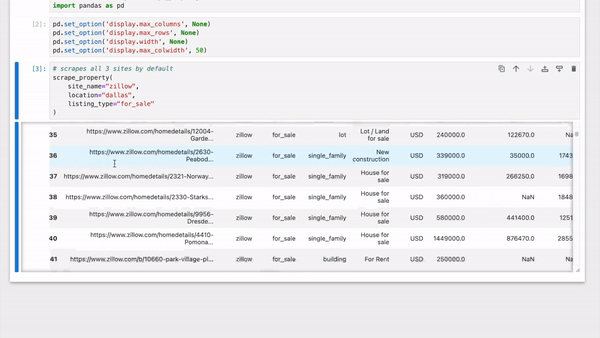
|
||||
|
||||
@@ -26,134 +30,78 @@ pip install -U homeharvest
|
||||
|
||||
```py
|
||||
from homeharvest import scrape_property
|
||||
from datetime import datetime
|
||||
|
||||
# Generate filename based on current timestamp
|
||||
current_timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
filename = f"HomeHarvest_{current_timestamp}.csv"
|
||||
|
||||
properties = scrape_property(
|
||||
location="San Diego, CA",
|
||||
listing_type="sold", # or (for_sale, for_rent, pending)
|
||||
past_days=30, # sold in last 30 days - listed in last 30 days if (for_sale, for_rent)
|
||||
|
||||
# property_type=['single_family','multi_family'],
|
||||
# date_from="2023-05-01", # alternative to past_days
|
||||
# date_to="2023-05-28",
|
||||
# foreclosure=True
|
||||
# mls_only=True, # only fetch MLS listings
|
||||
location="San Diego, CA",
|
||||
listing_type="sold", # for_sale, for_rent, pending
|
||||
past_days=30
|
||||
)
|
||||
print(f"Number of properties: {len(properties)}")
|
||||
|
||||
# Export to csv
|
||||
properties.to_csv(filename, index=False)
|
||||
print(properties.head())
|
||||
properties.to_csv("results.csv", index=False)
|
||||
print(f"Found {len(properties)} properties")
|
||||
```
|
||||
|
||||
### Flexible Location Formats
|
||||
```py
|
||||
# HomeHarvest supports any of these location formats:
|
||||
properties = scrape_property(location="92104") # Just zip code
|
||||
properties = scrape_property(location="San Diego") # Just city
|
||||
properties = scrape_property(location="San Diego, CA") # City, state
|
||||
properties = scrape_property(location="San Diego, California") # Full state name
|
||||
properties = scrape_property(location="1234 Main St, San Diego, CA 92104") # Full address
|
||||
|
||||
# You can also search for properties within a radius of a specific address
|
||||
# Accepts: zip code, city, "city, state", full address, etc.
|
||||
properties = scrape_property(
|
||||
location="1234 Main St, San Diego, CA 92104",
|
||||
radius=5.0 # 5 mile radius
|
||||
location="San Diego, CA", # or "92104", "San Diego", "1234 Main St, San Diego, CA 92104"
|
||||
radius=5.0 # Optional: search within radius (miles) of address
|
||||
)
|
||||
```
|
||||
|
||||
### Advanced Filtering Examples
|
||||
|
||||
#### Hour-Based Filtering
|
||||
#### Time-Based Filtering
|
||||
```py
|
||||
# Get properties listed in the last 24 hours
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
# Filter by hours or use datetime/timedelta objects
|
||||
properties = scrape_property(
|
||||
location="Austin, TX",
|
||||
listing_type="for_sale",
|
||||
past_hours=24
|
||||
)
|
||||
|
||||
# Get properties listed during specific hours (e.g., business hours)
|
||||
properties = scrape_property(
|
||||
location="Dallas, TX",
|
||||
listing_type="for_sale",
|
||||
datetime_from="2025-01-20T09:00:00",
|
||||
datetime_to="2025-01-20T17:00:00"
|
||||
past_hours=24, # or timedelta(hours=24) for Pythonic approach
|
||||
# date_from=datetime.now() - timedelta(days=7), # Alternative: datetime objects
|
||||
# date_to=datetime.now(), # Automatic hour precision detection
|
||||
)
|
||||
```
|
||||
|
||||
#### Property Filters
|
||||
```py
|
||||
# Filter by bedrooms, bathrooms, and square footage
|
||||
# Combine any filters: beds, baths, sqft, price, lot_sqft, year_built
|
||||
properties = scrape_property(
|
||||
location="San Francisco, CA",
|
||||
listing_type="for_sale",
|
||||
beds_min=2,
|
||||
beds_max=4,
|
||||
beds_min=3, beds_max=5,
|
||||
baths_min=2.0,
|
||||
sqft_min=1000,
|
||||
sqft_max=2500
|
||||
)
|
||||
|
||||
# Filter by price range
|
||||
properties = scrape_property(
|
||||
location="Phoenix, AZ",
|
||||
listing_type="for_sale",
|
||||
price_min=200000,
|
||||
price_max=500000
|
||||
)
|
||||
|
||||
# Filter by year built
|
||||
properties = scrape_property(
|
||||
location="Seattle, WA",
|
||||
listing_type="for_sale",
|
||||
sqft_min=1500, sqft_max=3000,
|
||||
price_min=300000, price_max=800000,
|
||||
year_built_min=2000,
|
||||
beds_min=3
|
||||
)
|
||||
|
||||
# Combine multiple filters
|
||||
properties = scrape_property(
|
||||
location="Denver, CO",
|
||||
listing_type="for_sale",
|
||||
beds_min=3,
|
||||
baths_min=2.0,
|
||||
sqft_min=1500,
|
||||
price_min=300000,
|
||||
price_max=600000,
|
||||
year_built_min=1990,
|
||||
lot_sqft_min=5000
|
||||
)
|
||||
```
|
||||
|
||||
#### Sorting Results
|
||||
#### Sorting & Listing Types
|
||||
```py
|
||||
# Sort by price (cheapest first)
|
||||
# Sort options: list_price, list_date, sqft, beds, baths, last_update_date
|
||||
# Listing types: "for_sale", "for_rent", "sold", "pending", list, or None (all)
|
||||
properties = scrape_property(
|
||||
location="Miami, FL",
|
||||
listing_type="for_sale",
|
||||
sort_by="list_price",
|
||||
sort_direction="asc",
|
||||
listing_type=["for_sale", "pending"], # Single string, list, or None
|
||||
sort_by="list_price", # Sort field
|
||||
sort_direction="asc", # "asc" or "desc"
|
||||
limit=100
|
||||
)
|
||||
```
|
||||
|
||||
# Sort by newest listings
|
||||
properties = scrape_property(
|
||||
location="Boston, MA",
|
||||
listing_type="for_sale",
|
||||
sort_by="list_date",
|
||||
sort_direction="desc"
|
||||
)
|
||||
|
||||
# Sort by square footage (largest first)
|
||||
#### Pagination Control
|
||||
```py
|
||||
# Sequential mode with early termination (more efficient for narrow filters)
|
||||
properties = scrape_property(
|
||||
location="Los Angeles, CA",
|
||||
listing_type="for_sale",
|
||||
sort_by="sqft",
|
||||
sort_direction="desc"
|
||||
updated_in_past_hours=2, # Narrow time window
|
||||
parallel=False # Fetch pages sequentially, stop when filters no longer match
|
||||
)
|
||||
```
|
||||
|
||||
@@ -192,30 +140,38 @@ for prop in properties[:5]:
|
||||
```
|
||||
Required
|
||||
├── location (str): Flexible location search - accepts any of these formats:
|
||||
- ZIP code: "92104"
|
||||
- City: "San Diego" or "San Francisco"
|
||||
- City, State (abbreviated or full): "San Diego, CA" or "San Diego, California"
|
||||
- Full address: "1234 Main St, San Diego, CA 92104"
|
||||
- Neighborhood: "Downtown San Diego"
|
||||
- County: "San Diego County"
|
||||
├── listing_type (option): Choose the type of listing.
|
||||
- 'for_rent'
|
||||
- 'for_sale'
|
||||
- 'sold'
|
||||
- 'pending' (for pending/contingent sales)
|
||||
|
||||
│ - ZIP code: "92104"
|
||||
│ - City: "San Diego" or "San Francisco"
|
||||
│ - City, State (abbreviated or full): "San Diego, CA" or "San Diego, California"
|
||||
│ - Full address: "1234 Main St, San Diego, CA 92104"
|
||||
│ - Neighborhood: "Downtown San Diego"
|
||||
│ - County: "San Diego County"
|
||||
│ - State (no support for abbreviated): "California"
|
||||
│
|
||||
├── listing_type (str | list[str] | None): Choose the type of listing.
|
||||
│ - 'for_sale'
|
||||
│ - 'for_rent'
|
||||
│ - 'sold'
|
||||
│ - 'pending'
|
||||
│ - 'off_market'
|
||||
│ - 'new_community'
|
||||
│ - 'other'
|
||||
│ - 'ready_to_build'
|
||||
│ - List of strings returns properties matching ANY status: ['for_sale', 'pending']
|
||||
│ - None returns all listing types
|
||||
│
|
||||
Optional
|
||||
├── property_type (list): Choose the type of properties.
|
||||
- 'single_family'
|
||||
- 'multi_family'
|
||||
- 'condos'
|
||||
- 'condo_townhome_rowhome_coop'
|
||||
- 'condo_townhome'
|
||||
- 'townhomes'
|
||||
- 'duplex_triplex'
|
||||
- 'farm'
|
||||
- 'land'
|
||||
- 'mobile'
|
||||
│ - 'single_family'
|
||||
│ - 'multi_family'
|
||||
│ - 'condos'
|
||||
│ - 'condo_townhome_rowhome_coop'
|
||||
│ - 'condo_townhome'
|
||||
│ - 'townhomes'
|
||||
│ - 'duplex_triplex'
|
||||
│ - 'farm'
|
||||
│ - 'land'
|
||||
│ - 'mobile'
|
||||
│
|
||||
├── return_type (option): Choose the return type.
|
||||
│ - 'pandas' (default)
|
||||
@@ -228,19 +184,28 @@ Optional
|
||||
├── past_days (integer): Number of past days to filter properties. Utilizes 'last_sold_date' for 'sold' listing types, and 'list_date' for others (for_rent, for_sale).
|
||||
│ Example: 30 (fetches properties listed/sold in the last 30 days)
|
||||
│
|
||||
├── past_hours (integer): Number of past hours to filter properties (more precise than past_days). Uses client-side filtering.
|
||||
│ Example: 24 (fetches properties from the last 24 hours)
|
||||
├── past_hours (integer | timedelta): Number of past hours to filter properties (more precise than past_days). Uses client-side filtering.
|
||||
│ Example: 24 or timedelta(hours=24) (fetches properties from the last 24 hours)
|
||||
│ Note: Cannot be used together with past_days or date_from/date_to
|
||||
│
|
||||
├── date_from, date_to (string): Start and end dates to filter properties listed or sold, both dates are required.
|
||||
| (use this to get properties in chunks as there's a 10k result limit)
|
||||
│ Format for both must be "YYYY-MM-DD".
|
||||
│ Example: "2023-05-01", "2023-05-15" (fetches properties listed/sold between these dates)
|
||||
│ (use this to get properties in chunks as there's a 10k result limit)
|
||||
│ Accepts multiple formats with automatic precision detection:
|
||||
│ - Date strings: "YYYY-MM-DD" (day precision)
|
||||
│ - Datetime strings: "YYYY-MM-DDTHH:MM:SS" (hour precision, uses client-side filtering)
|
||||
│ - date objects: date(2025, 1, 20) (day precision)
|
||||
│ - datetime objects: datetime(2025, 1, 20, 9, 0) (hour precision)
|
||||
│ Examples:
|
||||
│ Day precision: "2023-05-01", "2023-05-15"
|
||||
│ Hour precision: "2025-01-20T09:00:00", "2025-01-20T17:00:00"
|
||||
│
|
||||
├── datetime_from, datetime_to (string): ISO 8601 datetime strings for hour-precise filtering. Uses client-side filtering.
|
||||
│ Format: "YYYY-MM-DDTHH:MM:SS" or "YYYY-MM-DD"
|
||||
│ Example: "2025-01-20T09:00:00", "2025-01-20T17:00:00" (fetches properties between 9 AM and 5 PM)
|
||||
│ Note: Cannot be used together with date_from/date_to
|
||||
├── updated_since (datetime | str): Filter properties updated since a specific date/time (based on last_update_date field)
|
||||
│ Accepts datetime objects or ISO 8601 strings
|
||||
│ Example: updated_since=datetime(2025, 11, 10, 9, 0) or "2025-11-10T09:00:00"
|
||||
│
|
||||
├── updated_in_past_hours (integer | timedelta): Filter properties updated in the past X hours (based on last_update_date field)
|
||||
│ Accepts integer (hours) or timedelta object
|
||||
│ Example: updated_in_past_hours=24 or timedelta(hours=24)
|
||||
│
|
||||
├── beds_min, beds_max (integer): Filter by number of bedrooms
|
||||
│ Example: beds_min=2, beds_max=4 (2-4 bedrooms)
|
||||
@@ -261,7 +226,7 @@ Optional
|
||||
│ Example: year_built_min=2000, year_built_max=2024 (built between 2000-2024)
|
||||
│
|
||||
├── sort_by (string): Sort results by field
|
||||
│ Options: 'list_date', 'sold_date', 'list_price', 'sqft', 'beds', 'baths'
|
||||
│ Options: 'list_date', 'sold_date', 'list_price', 'sqft', 'beds', 'baths', 'last_update_date'
|
||||
│ Example: sort_by='list_price'
|
||||
│
|
||||
├── sort_direction (string): Sort direction, default is 'desc'
|
||||
@@ -278,7 +243,11 @@ Optional
|
||||
│
|
||||
├── exclude_pending (True/False): If set, excludes 'pending' properties from the 'for_sale' results unless listing_type is 'pending'
|
||||
│
|
||||
└── limit (integer): Limit the number of properties to fetch. Max & default is 10000.
|
||||
├── limit (integer): Limit the number of properties to fetch. Max & default is 10000.
|
||||
│
|
||||
├── offset (integer): Starting position for pagination within the 10k limit. Use with limit to fetch results in chunks.
|
||||
│
|
||||
└── parallel (True/False): Controls pagination strategy. Default is True (fetch pages in parallel for speed). Set to False for sequential fetching with early termination (useful for rate limiting or narrow time windows).
|
||||
```
|
||||
|
||||
### Property Schema
|
||||
@@ -325,6 +294,7 @@ Property
|
||||
│ ├── sold_price
|
||||
│ ├── last_sold_date # datetime (full timestamp: YYYY-MM-DD HH:MM:SS)
|
||||
│ ├── last_status_change_date # datetime (full timestamp: YYYY-MM-DD HH:MM:SS)
|
||||
│ ├── last_update_date # datetime (full timestamp: YYYY-MM-DD HH:MM:SS)
|
||||
│ ├── last_sold_price
|
||||
│ ├── price_per_sqft
|
||||
│ ├── new_construction
|
||||
|
||||
@@ -1,30 +1,37 @@
|
||||
import warnings
|
||||
import pandas as pd
|
||||
from datetime import datetime, timedelta, date
|
||||
from .core.scrapers import ScraperInput
|
||||
from .utils import process_result, ordered_properties, validate_input, validate_dates, validate_limit, validate_datetime, validate_filters, validate_sort
|
||||
from .utils import (
|
||||
process_result, ordered_properties, validate_input, validate_dates, validate_limit,
|
||||
validate_offset, validate_datetime, validate_filters, validate_sort, validate_last_update_filters,
|
||||
convert_to_datetime_string, extract_timedelta_hours, extract_timedelta_days, detect_precision_and_convert
|
||||
)
|
||||
from .core.scrapers.realtor import RealtorScraper
|
||||
from .core.scrapers.models import ListingType, SearchPropertyType, ReturnType, Property
|
||||
from typing import Union, Optional, List
|
||||
|
||||
def scrape_property(
|
||||
location: str,
|
||||
listing_type: str = "for_sale",
|
||||
listing_type: str | list[str] | None = None,
|
||||
return_type: str = "pandas",
|
||||
property_type: Optional[List[str]] = None,
|
||||
radius: float = None,
|
||||
mls_only: bool = False,
|
||||
past_days: int = None,
|
||||
past_days: int | timedelta = None,
|
||||
proxy: str = None,
|
||||
date_from: str = None,
|
||||
date_to: str = None,
|
||||
date_from: datetime | date | str = None,
|
||||
date_to: datetime | date | str = None,
|
||||
foreclosure: bool = None,
|
||||
extra_property_data: bool = True,
|
||||
exclude_pending: bool = False,
|
||||
limit: int = 10000,
|
||||
offset: int = 0,
|
||||
# New date/time filtering parameters
|
||||
past_hours: int = None,
|
||||
datetime_from: str = None,
|
||||
datetime_to: str = None,
|
||||
past_hours: int | timedelta = None,
|
||||
# New last_update_date filtering parameters
|
||||
updated_since: datetime | str = None,
|
||||
updated_in_past_hours: int | timedelta = None,
|
||||
# New property filtering parameters
|
||||
beds_min: int = None,
|
||||
beds_max: int = None,
|
||||
@@ -41,12 +48,16 @@ def scrape_property(
|
||||
# New sorting parameters
|
||||
sort_by: str = None,
|
||||
sort_direction: str = "desc",
|
||||
# Pagination control
|
||||
parallel: bool = True,
|
||||
) -> Union[pd.DataFrame, list[dict], list[Property]]:
|
||||
"""
|
||||
Scrape properties from Realtor.com based on a given location and listing type.
|
||||
|
||||
:param location: Location to search (e.g. "Dallas, TX", "85281", "2530 Al Lipscomb Way")
|
||||
:param listing_type: Listing Type (for_sale, for_rent, sold, pending)
|
||||
:param listing_type: Listing Type - can be a string, list of strings, or None.
|
||||
Options: for_sale, for_rent, sold, pending, off_market, new_community, other, ready_to_build
|
||||
Examples: "for_sale", ["for_sale", "pending"], None (returns all types)
|
||||
:param return_type: Return type (pandas, pydantic, raw)
|
||||
:param property_type: Property Type (single_family, multi_family, condos, condo_townhome_rowhome_coop, condo_townhome, townhomes, duplex_triplex, farm, land, mobile)
|
||||
:param radius: Get properties within _ (e.g. 1.0) miles. Only applicable for individual addresses.
|
||||
@@ -56,54 +67,118 @@ def scrape_property(
|
||||
- PENDING: Filters by pending_date. Contingent properties without pending_date are included.
|
||||
- SOLD: Filters by sold_date (when property was sold)
|
||||
- FOR_SALE/FOR_RENT: Filters by list_date (when property was listed)
|
||||
:param date_from, date_to: Get properties sold or listed (dependent on your listing_type) between these dates. format: 2021-01-28
|
||||
:param date_from, date_to: Get properties sold or listed (dependent on your listing_type) between these dates.
|
||||
Accepts multiple formats for flexible precision:
|
||||
- Date strings: "2025-01-20" (day-level precision)
|
||||
- Datetime strings: "2025-01-20T14:30:00" (hour-level precision)
|
||||
- date objects: date(2025, 1, 20) (day-level precision)
|
||||
- datetime objects: datetime(2025, 1, 20, 14, 30) (hour-level precision)
|
||||
The precision is automatically detected based on the input format.
|
||||
Timezone handling: Naive datetimes are treated as local time and automatically converted to UTC.
|
||||
Timezone-aware datetimes are converted to UTC. For best results, use timezone-aware datetimes.
|
||||
:param foreclosure: If set, fetches only foreclosure listings.
|
||||
:param extra_property_data: Increases requests by O(n). If set, this fetches additional property data (e.g. agent, broker, property evaluations etc.)
|
||||
:param exclude_pending: If true, this excludes pending or contingent properties from the results, unless listing type is pending.
|
||||
:param limit: Limit the number of results returned. Maximum is 10,000.
|
||||
:param offset: Starting position for pagination within the 10k limit (offset + limit cannot exceed 10,000). Use with limit to fetch results in chunks (e.g., offset=200, limit=200 fetches results 200-399). Should be a multiple of 200 (page size) for optimal performance. Default is 0. Note: Cannot be used to bypass the 10k API limit - use date ranges (date_from/date_to) to narrow searches and fetch more data.
|
||||
|
||||
New parameters:
|
||||
:param past_hours: Get properties in the last _ hours (requires client-side filtering)
|
||||
:param datetime_from, datetime_to: ISO 8601 datetime strings for precise time filtering (e.g. "2025-01-20T14:30:00")
|
||||
:param past_hours: Get properties in the last _ hours (requires client-side filtering). Accepts int or timedelta.
|
||||
:param updated_since: Filter by last_update_date (when property was last updated). Accepts datetime object or ISO 8601 string (client-side filtering).
|
||||
Timezone handling: Naive datetimes (like datetime.now()) are treated as local time and automatically converted to UTC.
|
||||
Timezone-aware datetimes are converted to UTC. Examples:
|
||||
- datetime.now() - uses your local timezone
|
||||
- datetime.now(timezone.utc) - uses UTC explicitly
|
||||
:param updated_in_past_hours: Filter by properties updated in the last _ hours. Accepts int or timedelta (client-side filtering)
|
||||
:param beds_min, beds_max: Filter by number of bedrooms
|
||||
:param baths_min, baths_max: Filter by number of bathrooms
|
||||
:param sqft_min, sqft_max: Filter by square footage
|
||||
:param price_min, price_max: Filter by listing price
|
||||
:param lot_sqft_min, lot_sqft_max: Filter by lot size
|
||||
:param year_built_min, year_built_max: Filter by year built
|
||||
:param sort_by: Sort results by field (list_date, sold_date, list_price, sqft, beds, baths)
|
||||
:param sort_by: Sort results by field (list_date, sold_date, list_price, sqft, beds, baths, last_update_date)
|
||||
:param sort_direction: Sort direction (asc, desc)
|
||||
:param parallel: Controls pagination strategy. True (default) = fetch all pages in parallel for maximum speed.
|
||||
False = fetch pages sequentially with early termination checks (useful for rate limiting or narrow time windows).
|
||||
Sequential mode will stop paginating as soon as time-based filters indicate no more matches are possible.
|
||||
|
||||
Note: past_days and past_hours also accept timedelta objects for more Pythonic usage.
|
||||
"""
|
||||
validate_input(listing_type)
|
||||
validate_dates(date_from, date_to)
|
||||
validate_limit(limit)
|
||||
validate_datetime(datetime_from)
|
||||
validate_datetime(datetime_to)
|
||||
validate_offset(offset, limit)
|
||||
validate_filters(
|
||||
beds_min, beds_max, baths_min, baths_max, sqft_min, sqft_max,
|
||||
price_min, price_max, lot_sqft_min, lot_sqft_max, year_built_min, year_built_max
|
||||
)
|
||||
validate_sort(sort_by, sort_direction)
|
||||
|
||||
# Validate new last_update_date filtering parameters
|
||||
validate_last_update_filters(
|
||||
convert_to_datetime_string(updated_since),
|
||||
extract_timedelta_hours(updated_in_past_hours)
|
||||
)
|
||||
|
||||
# Convert listing_type to appropriate format
|
||||
if listing_type is None:
|
||||
converted_listing_type = None
|
||||
elif isinstance(listing_type, list):
|
||||
converted_listing_type = [ListingType(lt.upper()) for lt in listing_type]
|
||||
else:
|
||||
converted_listing_type = ListingType(listing_type.upper())
|
||||
|
||||
# Convert date_from/date_to with precision detection
|
||||
converted_date_from, date_from_precision = detect_precision_and_convert(date_from)
|
||||
converted_date_to, date_to_precision = detect_precision_and_convert(date_to)
|
||||
|
||||
# Validate converted dates
|
||||
validate_dates(converted_date_from, converted_date_to)
|
||||
|
||||
# Convert datetime/timedelta objects to appropriate formats
|
||||
converted_past_days = extract_timedelta_days(past_days)
|
||||
converted_past_hours = extract_timedelta_hours(past_hours)
|
||||
converted_updated_since = convert_to_datetime_string(updated_since)
|
||||
converted_updated_in_past_hours = extract_timedelta_hours(updated_in_past_hours)
|
||||
|
||||
# Auto-apply optimal sort for time-based filters (unless user specified different sort)
|
||||
if (converted_updated_since or converted_updated_in_past_hours) and not sort_by:
|
||||
sort_by = "last_update_date"
|
||||
if not sort_direction:
|
||||
sort_direction = "desc" # Most recent first
|
||||
|
||||
# Auto-apply optimal sort for PENDING listings with date filters
|
||||
# PENDING API filtering is broken, so we rely on client-side filtering
|
||||
# Sorting by pending_date ensures efficient pagination with early termination
|
||||
elif (converted_listing_type == ListingType.PENDING and
|
||||
(converted_past_days or converted_past_hours or converted_date_from) and
|
||||
not sort_by):
|
||||
sort_by = "pending_date"
|
||||
if not sort_direction:
|
||||
sort_direction = "desc" # Most recent first
|
||||
|
||||
scraper_input = ScraperInput(
|
||||
location=location,
|
||||
listing_type=ListingType(listing_type.upper()),
|
||||
listing_type=converted_listing_type,
|
||||
return_type=ReturnType(return_type.lower()),
|
||||
property_type=[SearchPropertyType[prop.upper()] for prop in property_type] if property_type else None,
|
||||
proxy=proxy,
|
||||
radius=radius,
|
||||
mls_only=mls_only,
|
||||
last_x_days=past_days,
|
||||
date_from=date_from,
|
||||
date_to=date_to,
|
||||
last_x_days=converted_past_days,
|
||||
date_from=converted_date_from,
|
||||
date_to=converted_date_to,
|
||||
date_from_precision=date_from_precision,
|
||||
date_to_precision=date_to_precision,
|
||||
foreclosure=foreclosure,
|
||||
extra_property_data=extra_property_data,
|
||||
exclude_pending=exclude_pending,
|
||||
limit=limit,
|
||||
offset=offset,
|
||||
# New date/time filtering
|
||||
past_hours=past_hours,
|
||||
datetime_from=datetime_from,
|
||||
datetime_to=datetime_to,
|
||||
past_hours=converted_past_hours,
|
||||
# New last_update_date filtering
|
||||
updated_since=converted_updated_since,
|
||||
updated_in_past_hours=converted_updated_in_past_hours,
|
||||
# New property filtering
|
||||
beds_min=beds_min,
|
||||
beds_max=beds_max,
|
||||
@@ -120,6 +195,8 @@ def scrape_property(
|
||||
# New sorting
|
||||
sort_by=sort_by,
|
||||
sort_direction=sort_direction,
|
||||
# Pagination control
|
||||
parallel=parallel,
|
||||
)
|
||||
|
||||
site = RealtorScraper(scraper_input)
|
||||
|
||||
@@ -1,85 +0,0 @@
|
||||
import argparse
|
||||
import datetime
|
||||
from homeharvest import scrape_property
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(description="Home Harvest Property Scraper")
|
||||
parser.add_argument("location", type=str, help="Location to scrape (e.g., San Francisco, CA)")
|
||||
|
||||
parser.add_argument(
|
||||
"-l",
|
||||
"--listing_type",
|
||||
type=str,
|
||||
default="for_sale",
|
||||
choices=["for_sale", "for_rent", "sold", "pending"],
|
||||
help="Listing type to scrape",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-o",
|
||||
"--output",
|
||||
type=str,
|
||||
default="excel",
|
||||
choices=["excel", "csv"],
|
||||
help="Output format",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-f",
|
||||
"--filename",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Name of the output file (without extension)",
|
||||
)
|
||||
|
||||
parser.add_argument("-p", "--proxy", type=str, default=None, help="Proxy to use for scraping")
|
||||
parser.add_argument(
|
||||
"-d",
|
||||
"--days",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Sold/listed in last _ days filter.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-r",
|
||||
"--radius",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Get comparable properties within _ (eg. 0.0) miles. Only applicable for individual addresses.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"-m",
|
||||
"--mls_only",
|
||||
action="store_true",
|
||||
help="If set, fetches only MLS listings.",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
result = scrape_property(
|
||||
args.location,
|
||||
args.listing_type,
|
||||
radius=args.radius,
|
||||
proxy=args.proxy,
|
||||
mls_only=args.mls_only,
|
||||
past_days=args.days,
|
||||
)
|
||||
|
||||
if not args.filename:
|
||||
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
args.filename = f"HomeHarvest_{timestamp}"
|
||||
|
||||
if args.output == "excel":
|
||||
output_filename = f"{args.filename}.xlsx"
|
||||
result.to_excel(output_filename, index=False)
|
||||
print(f"Excel file saved as {output_filename}")
|
||||
elif args.output == "csv":
|
||||
output_filename = f"{args.filename}.csv"
|
||||
result.to_csv(output_filename, index=False)
|
||||
print(f"CSV file saved as {output_filename}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -13,7 +13,7 @@ from pydantic import BaseModel
|
||||
|
||||
class ScraperInput(BaseModel):
|
||||
location: str
|
||||
listing_type: ListingType
|
||||
listing_type: ListingType | list[ListingType] | None
|
||||
property_type: list[SearchPropertyType] | None = None
|
||||
radius: float | None = None
|
||||
mls_only: bool | None = False
|
||||
@@ -21,16 +21,21 @@ class ScraperInput(BaseModel):
|
||||
last_x_days: int | None = None
|
||||
date_from: str | None = None
|
||||
date_to: str | None = None
|
||||
date_from_precision: str | None = None # "day" or "hour"
|
||||
date_to_precision: str | None = None # "day" or "hour"
|
||||
foreclosure: bool | None = False
|
||||
extra_property_data: bool | None = True
|
||||
exclude_pending: bool | None = False
|
||||
limit: int = 10000
|
||||
offset: int = 0
|
||||
return_type: ReturnType = ReturnType.pandas
|
||||
|
||||
# New date/time filtering parameters
|
||||
past_hours: int | None = None
|
||||
datetime_from: str | None = None
|
||||
datetime_to: str | None = None
|
||||
|
||||
# New last_update_date filtering parameters
|
||||
updated_since: str | None = None
|
||||
updated_in_past_hours: int | None = None
|
||||
|
||||
# New property filtering parameters
|
||||
beds_min: int | None = None
|
||||
@@ -50,6 +55,9 @@ class ScraperInput(BaseModel):
|
||||
sort_by: str | None = None
|
||||
sort_direction: str = "desc"
|
||||
|
||||
# Pagination control
|
||||
parallel: bool = True
|
||||
|
||||
|
||||
class Scraper:
|
||||
session = None
|
||||
@@ -102,16 +110,21 @@ class Scraper:
|
||||
self.mls_only = scraper_input.mls_only
|
||||
self.date_from = scraper_input.date_from
|
||||
self.date_to = scraper_input.date_to
|
||||
self.date_from_precision = scraper_input.date_from_precision
|
||||
self.date_to_precision = scraper_input.date_to_precision
|
||||
self.foreclosure = scraper_input.foreclosure
|
||||
self.extra_property_data = scraper_input.extra_property_data
|
||||
self.exclude_pending = scraper_input.exclude_pending
|
||||
self.limit = scraper_input.limit
|
||||
self.offset = scraper_input.offset
|
||||
self.return_type = scraper_input.return_type
|
||||
|
||||
# New date/time filtering
|
||||
self.past_hours = scraper_input.past_hours
|
||||
self.datetime_from = scraper_input.datetime_from
|
||||
self.datetime_to = scraper_input.datetime_to
|
||||
|
||||
# New last_update_date filtering
|
||||
self.updated_since = scraper_input.updated_since
|
||||
self.updated_in_past_hours = scraper_input.updated_in_past_hours
|
||||
|
||||
# New property filtering
|
||||
self.beds_min = scraper_input.beds_min
|
||||
@@ -131,6 +144,9 @@ class Scraper:
|
||||
self.sort_by = scraper_input.sort_by
|
||||
self.sort_direction = scraper_input.sort_direction
|
||||
|
||||
# Pagination control
|
||||
self.parallel = scraper_input.parallel
|
||||
|
||||
def search(self) -> list[Union[Property | dict]]: ...
|
||||
|
||||
@staticmethod
|
||||
|
||||
@@ -43,6 +43,10 @@ class ListingType(Enum):
|
||||
FOR_RENT = "FOR_RENT"
|
||||
PENDING = "PENDING"
|
||||
SOLD = "SOLD"
|
||||
OFF_MARKET = "OFF_MARKET"
|
||||
NEW_COMMUNITY = "NEW_COMMUNITY"
|
||||
OTHER = "OTHER"
|
||||
READY_TO_BUILD = "READY_TO_BUILD"
|
||||
|
||||
|
||||
class PropertyType(Enum):
|
||||
@@ -193,6 +197,7 @@ class Property(BaseModel):
|
||||
pending_date: datetime | None = Field(None, description="The date listing went into pending state")
|
||||
last_sold_date: datetime | None = Field(None, description="Last time the Home was sold")
|
||||
last_status_change_date: datetime | None = Field(None, description="Last time the status of the listing changed")
|
||||
last_update_date: datetime | None = Field(None, description="Last time the home was updated")
|
||||
prc_sqft: int | None = None
|
||||
new_construction: bool | None = Field(None, description="Search for new construction homes")
|
||||
hoa_fee: int | None = Field(None, description="Search for homes where HOA fee is known and falls within specified range")
|
||||
|
||||
@@ -46,9 +46,17 @@ class RealtorScraper(Scraper):
|
||||
super().__init__(scraper_input)
|
||||
|
||||
def handle_location(self):
|
||||
# Get client_id from listing_type
|
||||
if self.listing_type is None:
|
||||
client_id = "for-sale"
|
||||
elif isinstance(self.listing_type, list):
|
||||
client_id = self.listing_type[0].value.lower().replace("_", "-") if self.listing_type else "for-sale"
|
||||
else:
|
||||
client_id = self.listing_type.value.lower().replace("_", "-")
|
||||
|
||||
params = {
|
||||
"input": self.location,
|
||||
"client_id": self.listing_type.value.lower().replace("_", "-"),
|
||||
"client_id": client_id,
|
||||
"limit": "1",
|
||||
"area_types": "city,state,county,postal_code,address,street,neighborhood,school,school_district,university,park",
|
||||
}
|
||||
@@ -134,34 +142,48 @@ class RealtorScraper(Scraper):
|
||||
date_param = ""
|
||||
|
||||
# Determine date field based on listing type
|
||||
if self.listing_type == ListingType.SOLD:
|
||||
date_field = "sold_date"
|
||||
elif self.listing_type in [ListingType.FOR_SALE, ListingType.FOR_RENT]:
|
||||
date_field = "list_date"
|
||||
else: # PENDING
|
||||
# Skip server-side date filtering for PENDING as both pending_date and contract_date
|
||||
# filters are broken in the API. Client-side filtering will be applied later.
|
||||
date_field = None
|
||||
# Convert listing_type to list for uniform handling
|
||||
if self.listing_type is None:
|
||||
listing_types = []
|
||||
date_field = None # When no listing_type is specified, skip date filtering
|
||||
elif isinstance(self.listing_type, list):
|
||||
listing_types = self.listing_type
|
||||
# For multiple types, we'll use a general date field or skip
|
||||
date_field = None # Skip date filtering for mixed types
|
||||
else:
|
||||
listing_types = [self.listing_type]
|
||||
# Determine date field for single type
|
||||
if self.listing_type == ListingType.SOLD:
|
||||
date_field = "sold_date"
|
||||
elif self.listing_type in [ListingType.FOR_SALE, ListingType.FOR_RENT]:
|
||||
date_field = "list_date"
|
||||
else: # PENDING or other types
|
||||
# Skip server-side date filtering for PENDING as both pending_date and contract_date
|
||||
# filters are broken in the API. Client-side filtering will be applied later.
|
||||
date_field = None
|
||||
|
||||
# Build date parameter (expand to full days if hour-based filtering is used)
|
||||
if date_field:
|
||||
if self.datetime_from or self.datetime_to:
|
||||
# Check if we have hour precision (need to extract date part for API, then filter client-side)
|
||||
has_hour_precision = (self.date_from_precision == "hour" or self.date_to_precision == "hour")
|
||||
|
||||
if has_hour_precision and (self.date_from or self.date_to):
|
||||
# Hour-based datetime filtering: extract date parts for API, client-side filter by hours
|
||||
from datetime import datetime
|
||||
|
||||
min_date = None
|
||||
max_date = None
|
||||
|
||||
if self.datetime_from:
|
||||
if self.date_from:
|
||||
try:
|
||||
dt_from = datetime.fromisoformat(self.datetime_from.replace('Z', '+00:00'))
|
||||
dt_from = datetime.fromisoformat(self.date_from.replace('Z', '+00:00'))
|
||||
min_date = dt_from.strftime("%Y-%m-%d")
|
||||
except (ValueError, AttributeError):
|
||||
pass
|
||||
|
||||
if self.datetime_to:
|
||||
if self.date_to:
|
||||
try:
|
||||
dt_to = datetime.fromisoformat(self.datetime_to.replace('Z', '+00:00'))
|
||||
dt_to = datetime.fromisoformat(self.date_to.replace('Z', '+00:00'))
|
||||
max_date = dt_to.strftime("%Y-%m-%d")
|
||||
except (ValueError, AttributeError):
|
||||
pass
|
||||
@@ -250,13 +272,15 @@ class RealtorScraper(Scraper):
|
||||
# Build sort parameter
|
||||
if self.sort_by:
|
||||
sort_param = f"sort: [{{ field: {self.sort_by}, direction: {self.sort_direction} }}]"
|
||||
elif self.listing_type == ListingType.SOLD:
|
||||
elif isinstance(self.listing_type, ListingType) and self.listing_type == ListingType.SOLD:
|
||||
sort_param = "sort: [{ field: sold_date, direction: desc }]"
|
||||
else:
|
||||
sort_param = "" #: prioritize normal fractal sort from realtor
|
||||
|
||||
# Handle PENDING with or_filters (applies if PENDING is in the list or is the single type)
|
||||
has_pending = ListingType.PENDING in listing_types
|
||||
pending_or_contingent_param = (
|
||||
"or_filters: { contingent: true, pending: true }" if self.listing_type == ListingType.PENDING else ""
|
||||
"or_filters: { contingent: true, pending: true }" if has_pending else ""
|
||||
)
|
||||
|
||||
# Build bucket parameter (only use fractal sort if no custom sort is specified)
|
||||
@@ -264,7 +288,27 @@ class RealtorScraper(Scraper):
|
||||
if not self.sort_by:
|
||||
bucket_param = 'bucket: { sort: "fractal_v1.1.3_fr" }'
|
||||
|
||||
listing_type = ListingType.FOR_SALE if self.listing_type == ListingType.PENDING else self.listing_type
|
||||
# Build status parameter
|
||||
# For PENDING, we need to query as FOR_SALE with or_filters for pending/contingent
|
||||
status_types = []
|
||||
for lt in listing_types:
|
||||
if lt == ListingType.PENDING:
|
||||
if ListingType.FOR_SALE not in status_types:
|
||||
status_types.append(ListingType.FOR_SALE)
|
||||
else:
|
||||
if lt not in status_types:
|
||||
status_types.append(lt)
|
||||
|
||||
# Build status parameter string
|
||||
if status_types:
|
||||
status_values = [st.value.lower() for st in status_types]
|
||||
if len(status_values) == 1:
|
||||
status_param = f"status: {status_values[0]}"
|
||||
else:
|
||||
status_param = f"status: [{', '.join(status_values)}]"
|
||||
else:
|
||||
status_param = "" # No status parameter means return all types
|
||||
|
||||
is_foreclosure = ""
|
||||
|
||||
if variables.get("foreclosure") is True:
|
||||
@@ -285,7 +329,7 @@ class RealtorScraper(Scraper):
|
||||
coordinates: $coordinates
|
||||
radius: $radius
|
||||
}
|
||||
status: %s
|
||||
%s
|
||||
%s
|
||||
%s
|
||||
%s
|
||||
@@ -297,7 +341,7 @@ class RealtorScraper(Scraper):
|
||||
) %s
|
||||
}""" % (
|
||||
is_foreclosure,
|
||||
listing_type.value.lower(),
|
||||
status_param,
|
||||
date_param,
|
||||
property_type_param,
|
||||
property_filters_param,
|
||||
@@ -320,7 +364,7 @@ class RealtorScraper(Scraper):
|
||||
county: $county
|
||||
postal_code: $postal_code
|
||||
state_code: $state_code
|
||||
status: %s
|
||||
%s
|
||||
%s
|
||||
%s
|
||||
%s
|
||||
@@ -333,7 +377,7 @@ class RealtorScraper(Scraper):
|
||||
) %s
|
||||
}""" % (
|
||||
is_foreclosure,
|
||||
listing_type.value.lower(),
|
||||
status_param,
|
||||
date_param,
|
||||
property_type_param,
|
||||
property_filters_param,
|
||||
@@ -405,13 +449,23 @@ class RealtorScraper(Scraper):
|
||||
|
||||
if self.return_type != ReturnType.raw:
|
||||
with ThreadPoolExecutor(max_workers=self.NUM_PROPERTY_WORKERS) as executor:
|
||||
futures = [executor.submit(process_property, result, self.mls_only, self.extra_property_data,
|
||||
self.exclude_pending, self.listing_type, get_key, process_extra_property_details) for result in properties_list]
|
||||
# Store futures with their indices to maintain sort order
|
||||
futures_with_indices = [
|
||||
(i, executor.submit(process_property, result, self.mls_only, self.extra_property_data,
|
||||
self.exclude_pending, self.listing_type, get_key, process_extra_property_details))
|
||||
for i, result in enumerate(properties_list)
|
||||
]
|
||||
|
||||
for future in as_completed(futures):
|
||||
# Collect results and sort by index to preserve API sort order
|
||||
results = []
|
||||
for idx, future in futures_with_indices:
|
||||
result = future.result()
|
||||
if result:
|
||||
properties.append(result)
|
||||
results.append((idx, result))
|
||||
|
||||
# Sort by index and extract properties in correct order
|
||||
results.sort(key=lambda x: x[0])
|
||||
properties = [result for idx, result in results]
|
||||
else:
|
||||
properties = properties_list
|
||||
|
||||
@@ -428,7 +482,7 @@ class RealtorScraper(Scraper):
|
||||
location_type = location_info["area_type"]
|
||||
|
||||
search_variables = {
|
||||
"offset": 0,
|
||||
"offset": self.offset,
|
||||
}
|
||||
|
||||
search_type = (
|
||||
@@ -472,38 +526,80 @@ class RealtorScraper(Scraper):
|
||||
total = result["total"]
|
||||
homes = result["properties"]
|
||||
|
||||
with ThreadPoolExecutor() as executor:
|
||||
futures = [
|
||||
executor.submit(
|
||||
self.general_search,
|
||||
variables=search_variables | {"offset": i},
|
||||
search_type=search_type,
|
||||
)
|
||||
for i in range(
|
||||
self.DEFAULT_PAGE_SIZE,
|
||||
min(total, self.limit),
|
||||
self.DEFAULT_PAGE_SIZE,
|
||||
)
|
||||
]
|
||||
# Fetch remaining pages based on parallel parameter
|
||||
if self.offset + self.DEFAULT_PAGE_SIZE < min(total, self.offset + self.limit):
|
||||
if self.parallel:
|
||||
# Parallel mode: Fetch all remaining pages in parallel
|
||||
with ThreadPoolExecutor() as executor:
|
||||
futures_with_offsets = [
|
||||
(i, executor.submit(
|
||||
self.general_search,
|
||||
variables=search_variables | {"offset": i},
|
||||
search_type=search_type,
|
||||
))
|
||||
for i in range(
|
||||
self.offset + self.DEFAULT_PAGE_SIZE,
|
||||
min(total, self.offset + self.limit),
|
||||
self.DEFAULT_PAGE_SIZE,
|
||||
)
|
||||
]
|
||||
|
||||
for future in as_completed(futures):
|
||||
homes.extend(future.result()["properties"])
|
||||
# Collect results and sort by offset to preserve API sort order
|
||||
results = []
|
||||
for offset, future in futures_with_offsets:
|
||||
results.append((offset, future.result()["properties"]))
|
||||
|
||||
results.sort(key=lambda x: x[0])
|
||||
for offset, properties in results:
|
||||
homes.extend(properties)
|
||||
else:
|
||||
# Sequential mode: Fetch pages one by one with early termination checks
|
||||
for current_offset in range(
|
||||
self.offset + self.DEFAULT_PAGE_SIZE,
|
||||
min(total, self.offset + self.limit),
|
||||
self.DEFAULT_PAGE_SIZE,
|
||||
):
|
||||
# Check if we should continue based on time-based filters
|
||||
if not self._should_fetch_more_pages(homes):
|
||||
break
|
||||
|
||||
result = self.general_search(
|
||||
variables=search_variables | {"offset": current_offset},
|
||||
search_type=search_type,
|
||||
)
|
||||
page_properties = result["properties"]
|
||||
homes.extend(page_properties)
|
||||
|
||||
# Apply client-side hour-based filtering if needed
|
||||
# (API only supports day-level filtering, so we post-filter for hour precision)
|
||||
if self.past_hours or self.datetime_from or self.datetime_to:
|
||||
has_hour_precision = (self.date_from_precision == "hour" or self.date_to_precision == "hour")
|
||||
if self.past_hours or has_hour_precision:
|
||||
homes = self._apply_hour_based_date_filter(homes)
|
||||
# Apply client-side date filtering for PENDING properties
|
||||
# (server-side filters are broken in the API)
|
||||
elif self.listing_type == ListingType.PENDING and (self.last_x_days or self.date_from):
|
||||
homes = self._apply_pending_date_filter(homes)
|
||||
|
||||
# Apply client-side filtering by last_update_date if specified
|
||||
if self.updated_since or self.updated_in_past_hours:
|
||||
homes = self._apply_last_update_date_filter(homes)
|
||||
|
||||
# Apply client-side sort to ensure results are properly ordered
|
||||
# This is necessary after filtering and to guarantee sort order across page boundaries
|
||||
if self.sort_by:
|
||||
homes = self._apply_sort(homes)
|
||||
|
||||
# Apply raw data filters (exclude_pending and mls_only) for raw return type
|
||||
# These filters are normally applied in process_property() but are bypassed for raw data
|
||||
if self.return_type == ReturnType.raw:
|
||||
homes = self._apply_raw_data_filters(homes)
|
||||
|
||||
return homes
|
||||
|
||||
def _apply_hour_based_date_filter(self, homes):
|
||||
"""Apply client-side hour-based date filtering for all listing types.
|
||||
|
||||
This is used when past_hours, datetime_from, or datetime_to are specified,
|
||||
This is used when past_hours or date_from/date_to have hour precision,
|
||||
since the API only supports day-level filtering.
|
||||
"""
|
||||
if not homes:
|
||||
@@ -517,17 +613,17 @@ class RealtorScraper(Scraper):
|
||||
if self.past_hours:
|
||||
cutoff_datetime = datetime.now() - timedelta(hours=self.past_hours)
|
||||
date_range = {'type': 'since', 'date': cutoff_datetime}
|
||||
elif self.datetime_from or self.datetime_to:
|
||||
elif self.date_from or self.date_to:
|
||||
try:
|
||||
from_datetime = None
|
||||
to_datetime = None
|
||||
|
||||
if self.datetime_from:
|
||||
from_datetime_str = self.datetime_from.replace('Z', '+00:00') if self.datetime_from.endswith('Z') else self.datetime_from
|
||||
if self.date_from:
|
||||
from_datetime_str = self.date_from.replace('Z', '+00:00') if self.date_from.endswith('Z') else self.date_from
|
||||
from_datetime = datetime.fromisoformat(from_datetime_str).replace(tzinfo=None)
|
||||
|
||||
if self.datetime_to:
|
||||
to_datetime_str = self.datetime_to.replace('Z', '+00:00') if self.datetime_to.endswith('Z') else self.datetime_to
|
||||
if self.date_to:
|
||||
to_datetime_str = self.date_to.replace('Z', '+00:00') if self.date_to.endswith('Z') else self.date_to
|
||||
to_datetime = datetime.fromisoformat(to_datetime_str).replace(tzinfo=None)
|
||||
|
||||
if from_datetime and to_datetime:
|
||||
@@ -659,18 +755,67 @@ class RealtorScraper(Scraper):
|
||||
if hasattr(home, 'flags') and home.flags:
|
||||
return getattr(home.flags, 'is_contingent', False)
|
||||
return False
|
||||
|
||||
|
||||
def _apply_last_update_date_filter(self, homes):
|
||||
"""Apply client-side filtering by last_update_date.
|
||||
|
||||
This is used when updated_since or updated_in_past_hours are specified.
|
||||
Filters properties based on when they were last updated.
|
||||
"""
|
||||
if not homes:
|
||||
return homes
|
||||
|
||||
from datetime import datetime, timedelta, timezone
|
||||
|
||||
# Determine date range for last_update_date filtering
|
||||
date_range = None
|
||||
|
||||
if self.updated_in_past_hours:
|
||||
# Use UTC now, strip timezone to match naive property dates
|
||||
cutoff_datetime = (datetime.now(timezone.utc) - timedelta(hours=self.updated_in_past_hours)).replace(tzinfo=None)
|
||||
date_range = {'type': 'since', 'date': cutoff_datetime}
|
||||
elif self.updated_since:
|
||||
try:
|
||||
since_datetime_str = self.updated_since.replace('Z', '+00:00') if self.updated_since.endswith('Z') else self.updated_since
|
||||
since_datetime = datetime.fromisoformat(since_datetime_str).replace(tzinfo=None)
|
||||
date_range = {'type': 'since', 'date': since_datetime}
|
||||
except (ValueError, AttributeError):
|
||||
return homes # If parsing fails, return unfiltered
|
||||
|
||||
if not date_range:
|
||||
return homes
|
||||
|
||||
filtered_homes = []
|
||||
|
||||
for home in homes:
|
||||
# Extract last_update_date from the property
|
||||
property_date = self._extract_date_from_home(home, 'last_update_date')
|
||||
|
||||
# Skip properties without last_update_date
|
||||
if property_date is None:
|
||||
continue
|
||||
|
||||
# Check if property date falls within the specified range
|
||||
if self._is_datetime_in_range(property_date, date_range):
|
||||
filtered_homes.append(home)
|
||||
|
||||
return filtered_homes
|
||||
|
||||
def _get_date_range(self):
|
||||
"""Get the date range for filtering based on instance parameters."""
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
from datetime import datetime, timedelta, timezone
|
||||
|
||||
if self.last_x_days:
|
||||
cutoff_date = datetime.now() - timedelta(days=self.last_x_days)
|
||||
# Use UTC now, strip timezone to match naive property dates
|
||||
cutoff_date = (datetime.now(timezone.utc) - timedelta(days=self.last_x_days)).replace(tzinfo=None)
|
||||
return {'type': 'since', 'date': cutoff_date}
|
||||
elif self.date_from and self.date_to:
|
||||
try:
|
||||
from_date = datetime.fromisoformat(self.date_from)
|
||||
to_date = datetime.fromisoformat(self.date_to)
|
||||
# Parse and strip timezone to match naive property dates
|
||||
from_date_str = self.date_from.replace('Z', '+00:00') if self.date_from.endswith('Z') else self.date_from
|
||||
to_date_str = self.date_to.replace('Z', '+00:00') if self.date_to.endswith('Z') else self.date_to
|
||||
from_date = datetime.fromisoformat(from_date_str).replace(tzinfo=None)
|
||||
to_date = datetime.fromisoformat(to_date_str).replace(tzinfo=None)
|
||||
return {'type': 'range', 'from_date': from_date, 'to_date': to_date}
|
||||
except ValueError:
|
||||
return None
|
||||
@@ -722,6 +867,174 @@ class RealtorScraper(Scraper):
|
||||
return date_range['from_date'] <= date_obj <= date_range['to_date']
|
||||
return False
|
||||
|
||||
def _should_fetch_more_pages(self, first_page):
|
||||
"""Determine if we should continue pagination based on first page results.
|
||||
|
||||
This optimization prevents unnecessary API calls when using time-based filters
|
||||
with date sorting. If the last property on page 1 is already outside the time
|
||||
window, all future pages will also be outside (due to sort order).
|
||||
|
||||
Args:
|
||||
first_page: List of properties from the first page
|
||||
|
||||
Returns:
|
||||
bool: True if we should continue pagination, False to stop early
|
||||
"""
|
||||
from datetime import datetime, timedelta, timezone
|
||||
|
||||
# Check for last_update_date filters
|
||||
if (self.updated_since or self.updated_in_past_hours) and self.sort_by == "last_update_date":
|
||||
if not first_page:
|
||||
return False
|
||||
|
||||
last_property = first_page[-1]
|
||||
last_date = self._extract_date_from_home(last_property, 'last_update_date')
|
||||
|
||||
if not last_date:
|
||||
return True
|
||||
|
||||
# Build date range for last_update_date filter
|
||||
if self.updated_since:
|
||||
try:
|
||||
cutoff_datetime = datetime.fromisoformat(self.updated_since.replace('Z', '+00:00') if self.updated_since.endswith('Z') else self.updated_since)
|
||||
# Strip timezone to match naive datetimes from _parse_date_value
|
||||
cutoff_datetime = cutoff_datetime.replace(tzinfo=None)
|
||||
date_range = {'type': 'since', 'date': cutoff_datetime}
|
||||
except ValueError:
|
||||
return True
|
||||
elif self.updated_in_past_hours:
|
||||
# Use UTC now, strip timezone to match naive property dates
|
||||
cutoff_datetime = (datetime.now(timezone.utc) - timedelta(hours=self.updated_in_past_hours)).replace(tzinfo=None)
|
||||
date_range = {'type': 'since', 'date': cutoff_datetime}
|
||||
else:
|
||||
return True
|
||||
|
||||
return self._is_datetime_in_range(last_date, date_range)
|
||||
|
||||
# Check for PENDING date filters
|
||||
if (self.listing_type == ListingType.PENDING and
|
||||
(self.last_x_days or self.past_hours or self.date_from) and
|
||||
self.sort_by == "pending_date"):
|
||||
|
||||
if not first_page:
|
||||
return False
|
||||
|
||||
last_property = first_page[-1]
|
||||
last_date = self._extract_date_from_home(last_property, 'pending_date')
|
||||
|
||||
if not last_date:
|
||||
return True
|
||||
|
||||
# Build date range for pending date filter
|
||||
date_range = self._get_date_range()
|
||||
if not date_range:
|
||||
return True
|
||||
|
||||
return self._is_datetime_in_range(last_date, date_range)
|
||||
|
||||
# No optimization applicable, continue pagination
|
||||
return True
|
||||
|
||||
def _apply_sort(self, homes):
|
||||
"""Apply client-side sorting to ensure results are properly ordered.
|
||||
|
||||
This is necessary because:
|
||||
1. Multi-page results need to be re-sorted after concatenation
|
||||
2. Filtering operations may disrupt the original sort order
|
||||
|
||||
Args:
|
||||
homes: List of properties (either dicts or Property objects)
|
||||
|
||||
Returns:
|
||||
Sorted list of properties
|
||||
"""
|
||||
if not homes or not self.sort_by:
|
||||
return homes
|
||||
|
||||
def get_sort_key(home):
|
||||
"""Extract the sort field value from a home (handles both dict and Property object)."""
|
||||
from datetime import datetime
|
||||
|
||||
if isinstance(home, dict):
|
||||
value = home.get(self.sort_by)
|
||||
else:
|
||||
# Property object
|
||||
value = getattr(home, self.sort_by, None)
|
||||
|
||||
# Handle None values - push them to the end
|
||||
if value is None:
|
||||
# Use a sentinel value that sorts to the end
|
||||
return (1, 0) if self.sort_direction == "desc" else (1, float('inf'))
|
||||
|
||||
# For datetime fields, convert string to datetime for proper sorting
|
||||
if self.sort_by in ['list_date', 'sold_date', 'pending_date', 'last_update_date']:
|
||||
if isinstance(value, str):
|
||||
try:
|
||||
# Handle timezone indicators
|
||||
date_value = value
|
||||
if date_value.endswith('Z'):
|
||||
date_value = date_value[:-1] + '+00:00'
|
||||
parsed_date = datetime.fromisoformat(date_value)
|
||||
# Normalize to timezone-naive for consistent comparison
|
||||
return 0, parsed_date.replace(tzinfo=None)
|
||||
except (ValueError, AttributeError):
|
||||
# If parsing fails, treat as None
|
||||
return (1, 0) if self.sort_direction == "desc" else (1, float('inf'))
|
||||
# Handle datetime objects directly (normalize timezone)
|
||||
if isinstance(value, datetime):
|
||||
return 0, value.replace(tzinfo=None)
|
||||
return 0, value
|
||||
|
||||
# For numeric fields, ensure we can compare
|
||||
return 0, value
|
||||
|
||||
# Sort the homes
|
||||
reverse = (self.sort_direction == "desc")
|
||||
sorted_homes = sorted(homes, key=get_sort_key, reverse=reverse)
|
||||
|
||||
return sorted_homes
|
||||
|
||||
def _apply_raw_data_filters(self, homes):
|
||||
"""Apply exclude_pending and mls_only filters for raw data returns.
|
||||
|
||||
These filters are normally applied in process_property(), but that function
|
||||
is bypassed when return_type="raw", so we need to apply them here instead.
|
||||
|
||||
Args:
|
||||
homes: List of properties (either dicts or Property objects)
|
||||
|
||||
Returns:
|
||||
Filtered list of properties
|
||||
"""
|
||||
if not homes:
|
||||
return homes
|
||||
|
||||
# Only filter raw data (dict objects)
|
||||
# Property objects have already been filtered in process_property()
|
||||
if homes and not isinstance(homes[0], dict):
|
||||
return homes
|
||||
|
||||
filtered_homes = []
|
||||
|
||||
for home in homes:
|
||||
# Apply exclude_pending filter
|
||||
if self.exclude_pending and self.listing_type != ListingType.PENDING:
|
||||
flags = home.get('flags', {})
|
||||
is_pending = flags.get('is_pending', False)
|
||||
is_contingent = flags.get('is_contingent', False)
|
||||
|
||||
if is_pending or is_contingent:
|
||||
continue # Skip this property
|
||||
|
||||
# Apply mls_only filter
|
||||
if self.mls_only:
|
||||
source = home.get('source', {})
|
||||
if not source or not source.get('id'):
|
||||
continue # Skip this property
|
||||
|
||||
filtered_homes.append(home)
|
||||
|
||||
return filtered_homes
|
||||
|
||||
|
||||
@retry(
|
||||
|
||||
@@ -126,6 +126,7 @@ def process_property(result: dict, mls_only: bool = False, extra_property_data:
|
||||
last_sold_date=(datetime.fromisoformat(result["last_sold_date"].replace('Z', '+00:00') if result["last_sold_date"].endswith('Z') else result["last_sold_date"]) if result.get("last_sold_date") else None),
|
||||
pending_date=(datetime.fromisoformat(result["pending_date"].replace('Z', '+00:00') if result["pending_date"].endswith('Z') else result["pending_date"]) if result.get("pending_date") else None),
|
||||
last_status_change_date=(datetime.fromisoformat(result["last_status_change_date"].replace('Z', '+00:00') if result["last_status_change_date"].endswith('Z') else result["last_status_change_date"]) if result.get("last_status_change_date") else None),
|
||||
last_update_date=(datetime.fromisoformat(result["last_update_date"].replace('Z', '+00:00') if result["last_update_date"].endswith('Z') else result["last_update_date"]) if result.get("last_update_date") else None),
|
||||
new_construction=result["flags"].get("is_new_construction") is True,
|
||||
hoa_fee=(result["hoa"]["fee"] if result.get("hoa") and isinstance(result["hoa"], dict) else None),
|
||||
latitude=(result["location"]["address"]["coordinate"].get("lat") if able_to_get_lat_long else None),
|
||||
|
||||
@@ -10,6 +10,7 @@ _SEARCH_HOMES_DATA_BASE = """{
|
||||
last_sold_price
|
||||
last_sold_date
|
||||
last_status_change_date
|
||||
last_update_date
|
||||
list_price
|
||||
list_price_max
|
||||
list_price_min
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
from __future__ import annotations
|
||||
import pandas as pd
|
||||
import warnings
|
||||
from datetime import datetime
|
||||
from .core.scrapers.models import Property, ListingType, Advertisers
|
||||
from .exceptions import InvalidListingType, InvalidDate
|
||||
@@ -37,6 +38,7 @@ ordered_properties = [
|
||||
"last_sold_date",
|
||||
"last_sold_price",
|
||||
"last_status_change_date",
|
||||
"last_update_date",
|
||||
"assessed_value",
|
||||
"estimated_value",
|
||||
"tax",
|
||||
@@ -155,24 +157,45 @@ def process_result(result: Property) -> pd.DataFrame:
|
||||
return properties_df[ordered_properties]
|
||||
|
||||
|
||||
def validate_input(listing_type: str) -> None:
|
||||
if listing_type.upper() not in ListingType.__members__:
|
||||
raise InvalidListingType(f"Provided listing type, '{listing_type}', does not exist.")
|
||||
def validate_input(listing_type: str | list[str] | None) -> None:
|
||||
if listing_type is None:
|
||||
return # None is valid - returns all types
|
||||
|
||||
if isinstance(listing_type, list):
|
||||
for lt in listing_type:
|
||||
if lt.upper() not in ListingType.__members__:
|
||||
raise InvalidListingType(f"Provided listing type, '{lt}', does not exist.")
|
||||
else:
|
||||
if listing_type.upper() not in ListingType.__members__:
|
||||
raise InvalidListingType(f"Provided listing type, '{listing_type}', does not exist.")
|
||||
|
||||
|
||||
def validate_dates(date_from: str | None, date_to: str | None) -> None:
|
||||
if isinstance(date_from, str) != isinstance(date_to, str):
|
||||
raise InvalidDate("Both date_from and date_to must be provided.")
|
||||
# Allow either date_from or date_to individually, or both together
|
||||
try:
|
||||
# Validate and parse date_from if provided
|
||||
date_from_obj = None
|
||||
if date_from:
|
||||
date_from_str = date_from.replace('Z', '+00:00') if date_from.endswith('Z') else date_from
|
||||
date_from_obj = datetime.fromisoformat(date_from_str)
|
||||
|
||||
if date_from and date_to:
|
||||
try:
|
||||
date_from_obj = datetime.strptime(date_from, "%Y-%m-%d")
|
||||
date_to_obj = datetime.strptime(date_to, "%Y-%m-%d")
|
||||
# Validate and parse date_to if provided
|
||||
date_to_obj = None
|
||||
if date_to:
|
||||
date_to_str = date_to.replace('Z', '+00:00') if date_to.endswith('Z') else date_to
|
||||
date_to_obj = datetime.fromisoformat(date_to_str)
|
||||
|
||||
if date_to_obj < date_from_obj:
|
||||
raise InvalidDate("date_to must be after date_from.")
|
||||
except ValueError:
|
||||
raise InvalidDate(f"Invalid date format or range")
|
||||
# If both provided, ensure date_to is after date_from
|
||||
if date_from_obj and date_to_obj and date_to_obj < date_from_obj:
|
||||
raise InvalidDate(f"date_to ('{date_to}') must be after date_from ('{date_from}').")
|
||||
|
||||
except ValueError as e:
|
||||
# Provide specific guidance on the expected format
|
||||
raise InvalidDate(
|
||||
f"Invalid date format. Expected ISO 8601 format. "
|
||||
f"Examples: '2025-01-20' (date only) or '2025-01-20T14:30:00' (with time). "
|
||||
f"Got: date_from='{date_from}', date_to='{date_to}'. Error: {e}"
|
||||
)
|
||||
|
||||
|
||||
def validate_limit(limit: int) -> None:
|
||||
@@ -182,21 +205,83 @@ def validate_limit(limit: int) -> None:
|
||||
raise ValueError("Property limit must be between 1 and 10,000.")
|
||||
|
||||
|
||||
def validate_datetime(datetime_str: str | None) -> None:
|
||||
"""Validate ISO 8601 datetime format."""
|
||||
if not datetime_str:
|
||||
def validate_offset(offset: int, limit: int = 10000) -> None:
|
||||
"""Validate offset parameter for pagination.
|
||||
|
||||
Args:
|
||||
offset: Starting position for results pagination
|
||||
limit: Maximum number of results to fetch
|
||||
|
||||
Raises:
|
||||
ValueError: If offset is invalid or if offset + limit exceeds API limit
|
||||
"""
|
||||
if offset is not None and offset < 0:
|
||||
raise ValueError("Offset must be non-negative (>= 0).")
|
||||
|
||||
# Check if offset + limit exceeds API's hard limit of 10,000
|
||||
if offset is not None and limit is not None and (offset + limit) > 10000:
|
||||
raise ValueError(
|
||||
f"offset ({offset}) + limit ({limit}) = {offset + limit} exceeds API maximum of 10,000. "
|
||||
f"The API cannot return results beyond position 10,000. "
|
||||
f"To fetch more results, narrow your search."
|
||||
)
|
||||
|
||||
# Warn if offset is not a multiple of 200 (API page size)
|
||||
if offset is not None and offset > 0 and offset % 200 != 0:
|
||||
warnings.warn(
|
||||
f"Offset should be a multiple of 200 (page size) for optimal performance. "
|
||||
f"Using offset {offset} may result in less efficient pagination.",
|
||||
UserWarning
|
||||
)
|
||||
|
||||
|
||||
def validate_datetime(datetime_value) -> None:
|
||||
"""Validate datetime value (accepts datetime objects or ISO 8601 strings)."""
|
||||
if datetime_value is None:
|
||||
return
|
||||
|
||||
# Already a datetime object - valid
|
||||
from datetime import datetime as dt, date
|
||||
if isinstance(datetime_value, (dt, date)):
|
||||
return
|
||||
|
||||
# Must be a string - validate ISO 8601 format
|
||||
if not isinstance(datetime_value, str):
|
||||
raise InvalidDate(
|
||||
f"Invalid datetime value. Expected datetime object, date object, or ISO 8601 string. "
|
||||
f"Got: {type(datetime_value).__name__}"
|
||||
)
|
||||
|
||||
try:
|
||||
# Try parsing as ISO 8601 datetime
|
||||
datetime.fromisoformat(datetime_str.replace('Z', '+00:00'))
|
||||
datetime.fromisoformat(datetime_value.replace('Z', '+00:00'))
|
||||
except (ValueError, AttributeError):
|
||||
raise InvalidDate(
|
||||
f"Invalid datetime format: '{datetime_str}'. "
|
||||
f"Invalid datetime format: '{datetime_value}'. "
|
||||
f"Expected ISO 8601 format (e.g., '2025-01-20T14:30:00' or '2025-01-20')."
|
||||
)
|
||||
|
||||
|
||||
def validate_last_update_filters(updated_since: str | None, updated_in_past_hours: int | None) -> None:
|
||||
"""Validate last_update_date filtering parameters."""
|
||||
if updated_since and updated_in_past_hours:
|
||||
raise ValueError(
|
||||
"Cannot use both 'updated_since' and 'updated_in_past_hours' parameters together. "
|
||||
"Please use only one method to filter by last_update_date."
|
||||
)
|
||||
|
||||
# Validate updated_since format if provided
|
||||
if updated_since:
|
||||
validate_datetime(updated_since)
|
||||
|
||||
# Validate updated_in_past_hours range if provided
|
||||
if updated_in_past_hours is not None:
|
||||
if updated_in_past_hours < 1:
|
||||
raise ValueError(
|
||||
f"updated_in_past_hours must be at least 1. Got: {updated_in_past_hours}"
|
||||
)
|
||||
|
||||
|
||||
def validate_filters(
|
||||
beds_min: int | None = None,
|
||||
beds_max: int | None = None,
|
||||
@@ -228,7 +313,7 @@ def validate_filters(
|
||||
|
||||
def validate_sort(sort_by: str | None, sort_direction: str | None = "desc") -> None:
|
||||
"""Validate sort parameters."""
|
||||
valid_sort_fields = ["list_date", "sold_date", "list_price", "sqft", "beds", "baths"]
|
||||
valid_sort_fields = ["list_date", "sold_date", "list_price", "sqft", "beds", "baths", "last_update_date"]
|
||||
valid_directions = ["asc", "desc"]
|
||||
|
||||
if sort_by and sort_by not in valid_sort_fields:
|
||||
@@ -242,3 +327,159 @@ def validate_sort(sort_by: str | None, sort_direction: str | None = "desc") -> N
|
||||
f"Invalid sort_direction value: '{sort_direction}'. "
|
||||
f"Valid options: {', '.join(valid_directions)}"
|
||||
)
|
||||
|
||||
|
||||
def convert_to_datetime_string(value) -> str | None:
|
||||
"""
|
||||
Convert datetime object or string to ISO 8601 string format with UTC timezone.
|
||||
|
||||
Accepts:
|
||||
- datetime.datetime objects (naive or timezone-aware)
|
||||
- Naive datetimes are treated as local time and converted to UTC
|
||||
- Timezone-aware datetimes are converted to UTC
|
||||
- datetime.date objects (treated as midnight UTC)
|
||||
- ISO 8601 strings (returned as-is)
|
||||
- None (returns None)
|
||||
|
||||
Returns ISO 8601 formatted string with UTC timezone or None.
|
||||
|
||||
Examples:
|
||||
>>> # Naive datetime (treated as local time)
|
||||
>>> convert_to_datetime_string(datetime(2025, 1, 20, 14, 30))
|
||||
'2025-01-20T22:30:00+00:00' # Assuming PST (UTC-8)
|
||||
|
||||
>>> # Timezone-aware datetime
|
||||
>>> convert_to_datetime_string(datetime(2025, 1, 20, 14, 30, tzinfo=timezone.utc))
|
||||
'2025-01-20T14:30:00+00:00'
|
||||
"""
|
||||
if value is None:
|
||||
return None
|
||||
|
||||
# Already a string - return as-is
|
||||
if isinstance(value, str):
|
||||
return value
|
||||
|
||||
# datetime.datetime object
|
||||
from datetime import datetime, date, timezone
|
||||
if isinstance(value, datetime):
|
||||
# Handle naive datetime - treat as local time and convert to UTC
|
||||
if value.tzinfo is None:
|
||||
# Convert naive datetime to aware local time, then to UTC
|
||||
local_aware = value.astimezone()
|
||||
utc_aware = local_aware.astimezone(timezone.utc)
|
||||
return utc_aware.isoformat()
|
||||
else:
|
||||
# Already timezone-aware, convert to UTC
|
||||
utc_aware = value.astimezone(timezone.utc)
|
||||
return utc_aware.isoformat()
|
||||
|
||||
# datetime.date object (convert to datetime at midnight UTC)
|
||||
if isinstance(value, date):
|
||||
utc_datetime = datetime.combine(value, datetime.min.time()).replace(tzinfo=timezone.utc)
|
||||
return utc_datetime.isoformat()
|
||||
|
||||
raise ValueError(
|
||||
f"Invalid datetime value. Expected datetime object, date object, or ISO 8601 string. "
|
||||
f"Got: {type(value).__name__}"
|
||||
)
|
||||
|
||||
|
||||
def extract_timedelta_hours(value) -> int | None:
|
||||
"""
|
||||
Extract hours from int or timedelta object.
|
||||
|
||||
Accepts:
|
||||
- int (returned as-is)
|
||||
- timedelta objects (converted to total hours)
|
||||
- None (returns None)
|
||||
|
||||
Returns integer hours or None.
|
||||
"""
|
||||
if value is None:
|
||||
return None
|
||||
|
||||
# Already an int - return as-is
|
||||
if isinstance(value, int):
|
||||
return value
|
||||
|
||||
# timedelta object - convert to hours
|
||||
from datetime import timedelta
|
||||
if isinstance(value, timedelta):
|
||||
return int(value.total_seconds() / 3600)
|
||||
|
||||
raise ValueError(
|
||||
f"Invalid past_hours value. Expected int or timedelta object. "
|
||||
f"Got: {type(value).__name__}"
|
||||
)
|
||||
|
||||
|
||||
def extract_timedelta_days(value) -> int | None:
|
||||
"""
|
||||
Extract days from int or timedelta object.
|
||||
|
||||
Accepts:
|
||||
- int (returned as-is)
|
||||
- timedelta objects (converted to total days)
|
||||
- None (returns None)
|
||||
|
||||
Returns integer days or None.
|
||||
"""
|
||||
if value is None:
|
||||
return None
|
||||
|
||||
# Already an int - return as-is
|
||||
if isinstance(value, int):
|
||||
return value
|
||||
|
||||
# timedelta object - convert to days
|
||||
from datetime import timedelta
|
||||
if isinstance(value, timedelta):
|
||||
return int(value.total_seconds() / 86400) # 86400 seconds in a day
|
||||
|
||||
raise ValueError(
|
||||
f"Invalid past_days value. Expected int or timedelta object. "
|
||||
f"Got: {type(value).__name__}"
|
||||
)
|
||||
|
||||
|
||||
def detect_precision_and_convert(value):
|
||||
"""
|
||||
Detect if input has time precision and convert to ISO string.
|
||||
|
||||
Accepts:
|
||||
- datetime.datetime objects → (ISO string, "hour")
|
||||
- datetime.date objects → (ISO string at midnight, "day")
|
||||
- ISO 8601 datetime strings with time → (string as-is, "hour")
|
||||
- Date-only strings "YYYY-MM-DD" → (string as-is, "day")
|
||||
- None → (None, None)
|
||||
|
||||
Returns:
|
||||
tuple: (iso_string, precision) where precision is "day" or "hour"
|
||||
"""
|
||||
if value is None:
|
||||
return (None, None)
|
||||
|
||||
from datetime import datetime as dt, date
|
||||
|
||||
# datetime.datetime object - has time precision
|
||||
if isinstance(value, dt):
|
||||
return (value.isoformat(), "hour")
|
||||
|
||||
# datetime.date object - day precision only
|
||||
if isinstance(value, date):
|
||||
# Convert to datetime at midnight
|
||||
return (dt.combine(value, dt.min.time()).isoformat(), "day")
|
||||
|
||||
# String - detect if it has time component
|
||||
if isinstance(value, str):
|
||||
# ISO 8601 datetime with time component (has 'T' and time)
|
||||
if 'T' in value:
|
||||
return (value, "hour")
|
||||
# Date-only string
|
||||
else:
|
||||
return (value, "day")
|
||||
|
||||
raise ValueError(
|
||||
f"Invalid date value. Expected datetime object, date object, or ISO 8601 string. "
|
||||
f"Got: {type(value).__name__}"
|
||||
)
|
||||
|
||||
@@ -1,14 +1,11 @@
|
||||
[tool.poetry]
|
||||
name = "homeharvest"
|
||||
version = "0.7.1"
|
||||
version = "0.8.4"
|
||||
description = "Real estate scraping library"
|
||||
authors = ["Zachary Hampton <zachary@bunsly.com>", "Cullen Watson <cullen@bunsly.com>"]
|
||||
homepage = "https://github.com/ZacharyHampton/HomeHarvest"
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.scripts]
|
||||
homeharvest = "homeharvest.cli:main"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.9"
|
||||
requests = "^2.32.4"
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
import pytz
|
||||
|
||||
from homeharvest import scrape_property, Property
|
||||
import pandas as pd
|
||||
|
||||
@@ -169,7 +171,13 @@ def test_realtor_without_extra_details():
|
||||
),
|
||||
]
|
||||
|
||||
assert not results[0].equals(results[1])
|
||||
# When extra_property_data=False, these fields should be None
|
||||
extra_fields = ["nearby_schools", "assessed_value", "tax", "tax_history"]
|
||||
|
||||
# Check that all extra fields are None when extra_property_data=False
|
||||
for field in extra_fields:
|
||||
if field in results[0].columns:
|
||||
assert results[0][field].isna().all(), f"Field '{field}' should be None when extra_property_data=False"
|
||||
|
||||
|
||||
def test_pr_zip_code():
|
||||
@@ -286,7 +294,7 @@ def test_return_type():
|
||||
"pydantic": [scrape_property(location="Surprise, AZ", listing_type="for_rent", limit=100, return_type="pydantic")],
|
||||
"raw": [
|
||||
scrape_property(location="Surprise, AZ", listing_type="for_rent", limit=100, return_type="raw"),
|
||||
scrape_property(location="66642", listing_type="for_rent", limit=100, return_type="raw"),
|
||||
scrape_property(location="85281", listing_type="for_rent", limit=100, return_type="raw"),
|
||||
],
|
||||
}
|
||||
|
||||
@@ -607,7 +615,7 @@ def test_past_hours_all_listing_types():
|
||||
|
||||
|
||||
def test_datetime_filtering():
|
||||
"""Test datetime_from and datetime_to parameters with hour precision"""
|
||||
"""Test date_from and date_to parameters with hour precision"""
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
# Get a recent date range (e.g., yesterday)
|
||||
@@ -618,28 +626,28 @@ def test_datetime_filtering():
|
||||
result = scrape_property(
|
||||
location="Dallas, TX",
|
||||
listing_type="for_sale",
|
||||
datetime_from=f"{date_str}T09:00:00",
|
||||
datetime_to=f"{date_str}T17:00:00",
|
||||
date_from=f"{date_str}T09:00:00",
|
||||
date_to=f"{date_str}T17:00:00",
|
||||
limit=30
|
||||
)
|
||||
|
||||
assert result is not None
|
||||
|
||||
# Test with only datetime_from
|
||||
# Test with only date_from
|
||||
result_from_only = scrape_property(
|
||||
location="Houston, TX",
|
||||
listing_type="for_sale",
|
||||
datetime_from=f"{date_str}T00:00:00",
|
||||
date_from=f"{date_str}T00:00:00",
|
||||
limit=30
|
||||
)
|
||||
|
||||
assert result_from_only is not None
|
||||
|
||||
# Test with only datetime_to
|
||||
# Test with only date_to
|
||||
result_to_only = scrape_property(
|
||||
location="Austin, TX",
|
||||
listing_type="for_sale",
|
||||
datetime_to=f"{date_str}T23:59:59",
|
||||
date_to=f"{date_str}T23:59:59",
|
||||
limit=30
|
||||
)
|
||||
|
||||
@@ -870,66 +878,111 @@ def test_combined_filters():
|
||||
|
||||
|
||||
def test_sorting_by_price():
|
||||
"""Test sorting by list_price - note API sorting may not be perfect"""
|
||||
"""Test sorting by list_price with actual sort order validation"""
|
||||
|
||||
# Sort ascending (cheapest first)
|
||||
# Sort ascending (cheapest first) with multi-page limit to test concatenation
|
||||
result_asc = scrape_property(
|
||||
location="Orlando, FL",
|
||||
listing_type="for_sale",
|
||||
sort_by="list_price",
|
||||
sort_direction="asc",
|
||||
limit=20
|
||||
limit=250 # Multi-page to test concatenation logic
|
||||
)
|
||||
|
||||
assert result_asc is not None and len(result_asc) > 0
|
||||
|
||||
# Verify ascending sort order (allow for None/NA values at the end)
|
||||
prices_asc = result_asc["list_price"].dropna().tolist()
|
||||
assert len(prices_asc) > 0, "No properties with prices found"
|
||||
assert prices_asc == sorted(prices_asc), f"Prices not in ascending order: {prices_asc[:10]}"
|
||||
|
||||
# Sort descending (most expensive first)
|
||||
result_desc = scrape_property(
|
||||
location="San Antonio, TX",
|
||||
listing_type="for_sale",
|
||||
sort_by="list_price",
|
||||
sort_direction="desc",
|
||||
limit=20
|
||||
limit=250 # Multi-page to test concatenation logic
|
||||
)
|
||||
|
||||
assert result_desc is not None and len(result_desc) > 0
|
||||
|
||||
# Note: Realtor API sorting may not be perfectly reliable for all search types
|
||||
# The test ensures the sort parameters don't cause errors, actual sort order may vary
|
||||
# Verify descending sort order (allow for None/NA values at the end)
|
||||
prices_desc = result_desc["list_price"].dropna().tolist()
|
||||
assert len(prices_desc) > 0, "No properties with prices found"
|
||||
assert prices_desc == sorted(prices_desc, reverse=True), f"Prices not in descending order: {prices_desc[:10]}"
|
||||
|
||||
|
||||
def test_sorting_by_date():
|
||||
"""Test sorting by list_date - note API sorting may not be perfect"""
|
||||
"""Test sorting by list_date with actual sort order validation"""
|
||||
|
||||
result = scrape_property(
|
||||
# Test descending (newest first) with multi-page limit
|
||||
result_desc = scrape_property(
|
||||
location="Columbus, OH",
|
||||
listing_type="for_sale",
|
||||
sort_by="list_date",
|
||||
sort_direction="desc", # Newest first
|
||||
limit=20
|
||||
limit=250 # Multi-page to test concatenation logic
|
||||
)
|
||||
|
||||
assert result is not None and len(result) > 0
|
||||
assert result_desc is not None and len(result_desc) > 0
|
||||
|
||||
# Test ensures sort parameter doesn't cause errors
|
||||
# Note: Realtor API sorting may not be perfectly reliable for all search types
|
||||
# Verify descending sort order (allow for None/NA values at the end)
|
||||
dates_desc = result_desc["list_date"].dropna().tolist()
|
||||
assert len(dates_desc) > 0, "No properties with dates found"
|
||||
assert dates_desc == sorted(dates_desc, reverse=True), f"Dates not in descending order (newest first): {dates_desc[:10]}"
|
||||
|
||||
# Test ascending (oldest first)
|
||||
result_asc = scrape_property(
|
||||
location="Columbus, OH",
|
||||
listing_type="for_sale",
|
||||
sort_by="list_date",
|
||||
sort_direction="asc", # Oldest first
|
||||
limit=250
|
||||
)
|
||||
|
||||
assert result_asc is not None and len(result_asc) > 0
|
||||
|
||||
# Verify ascending sort order
|
||||
dates_asc = result_asc["list_date"].dropna().tolist()
|
||||
assert len(dates_asc) > 0, "No properties with dates found"
|
||||
assert dates_asc == sorted(dates_asc), f"Dates not in ascending order (oldest first): {dates_asc[:10]}"
|
||||
|
||||
|
||||
def test_sorting_by_sqft():
|
||||
"""Test sorting by square footage - note API sorting may not be perfect"""
|
||||
"""Test sorting by square footage with actual sort order validation"""
|
||||
|
||||
result = scrape_property(
|
||||
# Test descending (largest first) with multi-page limit
|
||||
result_desc = scrape_property(
|
||||
location="Indianapolis, IN",
|
||||
listing_type="for_sale",
|
||||
sort_by="sqft",
|
||||
sort_direction="desc", # Largest first
|
||||
limit=20
|
||||
limit=250 # Multi-page to test concatenation logic
|
||||
)
|
||||
|
||||
assert result is not None and len(result) > 0
|
||||
assert result_desc is not None and len(result_desc) > 0
|
||||
|
||||
# Test ensures sort parameter doesn't cause errors
|
||||
# Note: Realtor API sorting may not be perfectly reliable for all search types
|
||||
# Verify descending sort order (allow for None/NA values at the end)
|
||||
sqfts_desc = result_desc["sqft"].dropna().tolist()
|
||||
assert len(sqfts_desc) > 0, "No properties with sqft found"
|
||||
assert sqfts_desc == sorted(sqfts_desc, reverse=True), f"Square footages not in descending order: {sqfts_desc[:10]}"
|
||||
|
||||
# Test ascending (smallest first)
|
||||
result_asc = scrape_property(
|
||||
location="Indianapolis, IN",
|
||||
listing_type="for_sale",
|
||||
sort_by="sqft",
|
||||
sort_direction="asc", # Smallest first
|
||||
limit=250
|
||||
)
|
||||
|
||||
assert result_asc is not None and len(result_asc) > 0
|
||||
|
||||
# Verify ascending sort order
|
||||
sqfts_asc = result_asc["sqft"].dropna().tolist()
|
||||
assert len(sqfts_asc) > 0, "No properties with sqft found"
|
||||
assert sqfts_asc == sorted(sqfts_asc), f"Square footages not in ascending order: {sqfts_asc[:10]}"
|
||||
|
||||
|
||||
def test_filter_validation_errors():
|
||||
@@ -1061,8 +1114,10 @@ def test_last_status_change_date_field():
|
||||
)
|
||||
|
||||
assert result_pending is not None
|
||||
assert "last_status_change_date" in result_pending.columns, \
|
||||
"last_status_change_date column should be present in PENDING results"
|
||||
# Only check columns if we have results (empty DataFrame has no columns)
|
||||
if len(result_pending) > 0:
|
||||
assert "last_status_change_date" in result_pending.columns, \
|
||||
"last_status_change_date column should be present in PENDING results"
|
||||
|
||||
# Test 3: Field is present in FOR_SALE listings
|
||||
result_for_sale = scrape_property(
|
||||
@@ -1224,4 +1279,318 @@ def test_last_status_change_date_hour_filtering():
|
||||
assert pending_date >= cutoff_time, \
|
||||
f"PENDING property pending_date {pending_date} should be within 48 hours of {cutoff_time}"
|
||||
except (ValueError, TypeError):
|
||||
pass # Skip if parsing fails
|
||||
pass # Skip if parsing fails
|
||||
|
||||
|
||||
def test_exclude_pending_with_raw_data():
|
||||
"""Test that exclude_pending parameter works correctly with return_type='raw'"""
|
||||
|
||||
# Query for sale properties with exclude_pending=True and raw data
|
||||
result = scrape_property(
|
||||
location="Phoenix, AZ",
|
||||
listing_type="for_sale",
|
||||
exclude_pending=True,
|
||||
return_type="raw",
|
||||
limit=50
|
||||
)
|
||||
|
||||
assert result is not None and len(result) > 0
|
||||
|
||||
# Verify that no pending or contingent properties are in the results
|
||||
for prop in result:
|
||||
flags = prop.get('flags', {})
|
||||
is_pending = flags.get('is_pending', False)
|
||||
is_contingent = flags.get('is_contingent', False)
|
||||
|
||||
assert not is_pending, f"Property {prop.get('property_id')} should not be pending when exclude_pending=True"
|
||||
assert not is_contingent, f"Property {prop.get('property_id')} should not be contingent when exclude_pending=True"
|
||||
|
||||
|
||||
def test_mls_only_with_raw_data():
|
||||
"""Test that mls_only parameter works correctly with return_type='raw'"""
|
||||
|
||||
# Query with mls_only=True and raw data
|
||||
result = scrape_property(
|
||||
location="Dallas, TX",
|
||||
listing_type="for_sale",
|
||||
mls_only=True,
|
||||
return_type="raw",
|
||||
limit=50
|
||||
)
|
||||
|
||||
assert result is not None and len(result) > 0
|
||||
|
||||
# Verify that all properties have MLS IDs (stored in source.id)
|
||||
for prop in result:
|
||||
source = prop.get('source', {})
|
||||
mls_id = source.get('id') if source else None
|
||||
|
||||
assert mls_id is not None and mls_id != "", \
|
||||
f"Property {prop.get('property_id')} should have an MLS ID (source.id) when mls_only=True, got: {mls_id}"
|
||||
|
||||
|
||||
def test_combined_filters_with_raw_data():
|
||||
"""Test that both exclude_pending and mls_only work together with return_type='raw'"""
|
||||
|
||||
# Query with both filters enabled and raw data
|
||||
result = scrape_property(
|
||||
location="Austin, TX",
|
||||
listing_type="for_sale",
|
||||
exclude_pending=True,
|
||||
mls_only=True,
|
||||
return_type="raw",
|
||||
limit=30
|
||||
)
|
||||
|
||||
assert result is not None and len(result) > 0
|
||||
|
||||
# Verify both filters are applied
|
||||
for prop in result:
|
||||
# Check exclude_pending filter
|
||||
flags = prop.get('flags', {})
|
||||
is_pending = flags.get('is_pending', False)
|
||||
is_contingent = flags.get('is_contingent', False)
|
||||
|
||||
assert not is_pending, f"Property {prop.get('property_id')} should not be pending"
|
||||
assert not is_contingent, f"Property {prop.get('property_id')} should not be contingent"
|
||||
|
||||
# Check mls_only filter
|
||||
source = prop.get('source', {})
|
||||
mls_id = source.get('id') if source else None
|
||||
|
||||
assert mls_id is not None and mls_id != "", \
|
||||
f"Property {prop.get('property_id')} should have an MLS ID (source.id)"
|
||||
|
||||
|
||||
def test_updated_since_filtering():
|
||||
"""Test the updated_since parameter for filtering by last_update_date"""
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
# Test 1: Filter by last update in past 10 minutes (user's example)
|
||||
cutoff_time = datetime.now() - timedelta(minutes=10)
|
||||
result_10min = scrape_property(
|
||||
location="California",
|
||||
updated_since=cutoff_time,
|
||||
sort_by="last_update_date",
|
||||
sort_direction="desc",
|
||||
limit=100
|
||||
)
|
||||
|
||||
assert result_10min is not None
|
||||
print(f"\n10-minute window returned {len(result_10min)} properties")
|
||||
|
||||
# Test 2: Verify all results have last_update_date within range
|
||||
if len(result_10min) > 0:
|
||||
for idx in range(min(10, len(result_10min))):
|
||||
update_date_str = result_10min.iloc[idx]["last_update_date"]
|
||||
if pd.notna(update_date_str):
|
||||
try:
|
||||
# Handle timezone-aware datetime strings
|
||||
date_str = str(update_date_str)
|
||||
if '+' in date_str or date_str.endswith('Z'):
|
||||
# Remove timezone for comparison with naive cutoff_time
|
||||
date_str = date_str.replace('+00:00', '').replace('Z', '')
|
||||
update_date = datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S")
|
||||
|
||||
assert update_date >= cutoff_time, \
|
||||
f"Property last_update_date {update_date} should be >= {cutoff_time}"
|
||||
print(f"Property {idx}: last_update_date = {update_date} (valid)")
|
||||
except (ValueError, TypeError) as e:
|
||||
print(f"Warning: Could not parse date {update_date_str}: {e}")
|
||||
|
||||
# Test 3: Compare different time windows
|
||||
result_1hour = scrape_property(
|
||||
location="California",
|
||||
updated_since=datetime.now() - timedelta(hours=1),
|
||||
limit=50
|
||||
)
|
||||
|
||||
result_24hours = scrape_property(
|
||||
location="California",
|
||||
updated_since=datetime.now() - timedelta(hours=24),
|
||||
limit=50
|
||||
)
|
||||
|
||||
print(f"1-hour window: {len(result_1hour)} properties")
|
||||
print(f"24-hour window: {len(result_24hours)} properties")
|
||||
|
||||
# Longer time window should return same or more results
|
||||
if len(result_1hour) > 0 and len(result_24hours) > 0:
|
||||
assert len(result_1hour) <= len(result_24hours), \
|
||||
"1-hour filter should return <= 24-hour results"
|
||||
|
||||
# Test 4: Verify sorting works with filtering
|
||||
if len(result_10min) > 1:
|
||||
# Get non-null dates
|
||||
dates = []
|
||||
for idx in range(len(result_10min)):
|
||||
date_str = result_10min.iloc[idx]["last_update_date"]
|
||||
if pd.notna(date_str):
|
||||
try:
|
||||
# Handle timezone-aware datetime strings
|
||||
clean_date_str = str(date_str)
|
||||
if '+' in clean_date_str or clean_date_str.endswith('Z'):
|
||||
clean_date_str = clean_date_str.replace('+00:00', '').replace('Z', '')
|
||||
dates.append(datetime.strptime(clean_date_str, "%Y-%m-%d %H:%M:%S"))
|
||||
except (ValueError, TypeError):
|
||||
pass
|
||||
|
||||
if len(dates) > 1:
|
||||
# Check if sorted descending
|
||||
for i in range(len(dates) - 1):
|
||||
assert dates[i] >= dates[i + 1], \
|
||||
f"Results should be sorted by last_update_date descending: {dates[i]} >= {dates[i+1]}"
|
||||
|
||||
|
||||
def test_updated_since_optimization():
|
||||
"""Test that updated_since optimization works (auto-sort + early termination)"""
|
||||
from datetime import datetime, timedelta
|
||||
import time
|
||||
|
||||
# Test 1: Verify auto-sort is applied when using updated_since without explicit sort
|
||||
start_time = time.time()
|
||||
result = scrape_property(
|
||||
location="California",
|
||||
updated_since=datetime.now() - timedelta(minutes=5),
|
||||
# NO sort_by specified - should auto-apply sort_by="last_update_date"
|
||||
limit=50
|
||||
)
|
||||
elapsed_time = time.time() - start_time
|
||||
|
||||
print(f"\nAuto-sort test: {len(result)} properties in {elapsed_time:.2f}s")
|
||||
|
||||
# Should complete quickly due to early termination optimization (<5 seconds)
|
||||
assert elapsed_time < 5.0, f"Query should be fast with optimization, took {elapsed_time:.2f}s"
|
||||
|
||||
# Verify results are sorted by last_update_date (proving auto-sort worked)
|
||||
if len(result) > 1:
|
||||
dates = []
|
||||
for idx in range(min(10, len(result))):
|
||||
date_str = result.iloc[idx]["last_update_date"]
|
||||
if pd.notna(date_str):
|
||||
try:
|
||||
clean_date_str = str(date_str)
|
||||
if '+' in clean_date_str or clean_date_str.endswith('Z'):
|
||||
clean_date_str = clean_date_str.replace('+00:00', '').replace('Z', '')
|
||||
dates.append(datetime.strptime(clean_date_str, "%Y-%m-%d %H:%M:%S"))
|
||||
except (ValueError, TypeError):
|
||||
pass
|
||||
|
||||
if len(dates) > 1:
|
||||
# Verify descending order (most recent first)
|
||||
for i in range(len(dates) - 1):
|
||||
assert dates[i] >= dates[i + 1], \
|
||||
"Auto-applied sort should order by last_update_date descending"
|
||||
|
||||
print("Auto-sort optimization verified ✓")
|
||||
|
||||
|
||||
def test_pending_date_optimization():
|
||||
"""Test that PENDING + date filters get auto-sort and early termination"""
|
||||
from datetime import datetime, timedelta
|
||||
import time
|
||||
|
||||
# Test: Verify auto-sort is applied for PENDING with past_days
|
||||
start_time = time.time()
|
||||
result = scrape_property(
|
||||
location="California",
|
||||
listing_type="pending",
|
||||
past_days=7,
|
||||
# NO sort_by specified - should auto-apply sort_by="pending_date"
|
||||
limit=50
|
||||
)
|
||||
elapsed_time = time.time() - start_time
|
||||
|
||||
print(f"\nPENDING auto-sort test: {len(result)} properties in {elapsed_time:.2f}s")
|
||||
|
||||
# Should complete quickly due to optimization (<10 seconds)
|
||||
assert elapsed_time < 10.0, f"PENDING query should be fast with optimization, took {elapsed_time:.2f}s"
|
||||
|
||||
# Verify results are sorted by pending_date (proving auto-sort worked)
|
||||
if len(result) > 1:
|
||||
dates = []
|
||||
for idx in range(min(10, len(result))):
|
||||
date_str = result.iloc[idx]["pending_date"]
|
||||
if pd.notna(date_str):
|
||||
try:
|
||||
clean_date_str = str(date_str)
|
||||
if '+' in clean_date_str or clean_date_str.endswith('Z'):
|
||||
clean_date_str = clean_date_str.replace('+00:00', '').replace('Z', '')
|
||||
dates.append(datetime.strptime(clean_date_str, "%Y-%m-%d %H:%M:%S"))
|
||||
except (ValueError, TypeError):
|
||||
pass
|
||||
|
||||
if len(dates) > 1:
|
||||
# Verify descending order (most recent first)
|
||||
for i in range(len(dates) - 1):
|
||||
assert dates[i] >= dates[i + 1], \
|
||||
"PENDING auto-applied sort should order by pending_date descending"
|
||||
|
||||
print("PENDING optimization verified ✓")
|
||||
|
||||
|
||||
def test_basic_last_update_date():
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
# Test with naive datetime (treated as local time)
|
||||
now = datetime.now()
|
||||
|
||||
properties = scrape_property(
|
||||
"California",
|
||||
updated_since=now - timedelta(minutes=10),
|
||||
sort_by="last_update_date",
|
||||
sort_direction="desc"
|
||||
)
|
||||
|
||||
# Convert now to timezone-aware for comparison with UTC dates in DataFrame
|
||||
now_utc = now.astimezone(tz=pytz.timezone("UTC"))
|
||||
|
||||
# Check all last_update_date values are <= now
|
||||
assert (properties["last_update_date"] <= now_utc).all()
|
||||
|
||||
# Verify we got some results
|
||||
assert len(properties) > 0
|
||||
|
||||
|
||||
def test_timezone_aware_last_update_date():
|
||||
"""Test that timezone-aware datetimes work correctly for updated_since"""
|
||||
from datetime import datetime, timedelta, timezone
|
||||
|
||||
# Test with timezone-aware datetime (explicit UTC)
|
||||
now_utc = datetime.now(timezone.utc)
|
||||
|
||||
properties = scrape_property(
|
||||
"California",
|
||||
updated_since=now_utc - timedelta(minutes=10),
|
||||
sort_by="last_update_date",
|
||||
sort_direction="desc"
|
||||
)
|
||||
|
||||
# Check all last_update_date values are <= now
|
||||
assert (properties["last_update_date"] <= now_utc).all()
|
||||
|
||||
# Verify we got some results
|
||||
assert len(properties) > 0
|
||||
|
||||
|
||||
def test_timezone_handling_date_range():
|
||||
"""Test timezone handling for date_from and date_to parameters"""
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
# Test with naive datetimes for date range (PENDING properties)
|
||||
now = datetime.now()
|
||||
three_days_ago = now - timedelta(days=3)
|
||||
|
||||
properties = scrape_property(
|
||||
"California",
|
||||
listing_type="pending",
|
||||
date_from=three_days_ago,
|
||||
date_to=now
|
||||
)
|
||||
|
||||
# Verify we got results and they're within the date range
|
||||
if len(properties) > 0:
|
||||
# Convert now to UTC for comparison
|
||||
now_utc = now.astimezone(tz=pytz.timezone("UTC"))
|
||||
assert (properties["pending_date"] <= now_utc).all()
|
||||
|
||||
|
||||
Reference in New Issue
Block a user