mirror of
https://github.com/Bunsly/HomeHarvest.git
synced 2026-03-05 12:04:31 -08:00
Compare commits
24 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e8d9235ee6 | ||
|
|
043f091158 | ||
|
|
eae8108978 | ||
|
|
0a39357a07 | ||
|
|
8f06d46ddb | ||
|
|
0dae14ccfc | ||
|
|
9aaabdd5d8 | ||
|
|
cdf41fe9f2 | ||
|
|
1f0feb836d | ||
|
|
5f31beda46 | ||
|
|
fd9cdea499 | ||
|
|
93a1cbe17f | ||
|
|
49d27943c4 | ||
|
|
05fca9b7e6 | ||
|
|
20ce44fb3a | ||
|
|
52017c1bb5 | ||
|
|
dba1c03081 | ||
|
|
1fc2d8c549 | ||
|
|
02d112eea0 | ||
|
|
30e510882b | ||
|
|
78b56c2cac | ||
|
|
087854a688 | ||
|
|
80586467a8 | ||
|
|
3494b152b8 |
3
.gitignore
vendored
3
.gitignore
vendored
@@ -3,4 +3,5 @@
|
||||
**/__pycache__/
|
||||
**/.pytest_cache/
|
||||
*.pyc
|
||||
/.ipynb_checkpoints/
|
||||
/.ipynb_checkpoints/
|
||||
*.csv
|
||||
@@ -55,7 +55,7 @@
|
||||
" location=\"2530 Al Lipscomb Way\",\n",
|
||||
" site_name=\"zillow\",\n",
|
||||
" listing_type=\"for_sale\"\n",
|
||||
"),"
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
50
README.md
50
README.md
@@ -9,17 +9,36 @@
|
||||
|
||||
- Scrapes properties from **Zillow**, **Realtor.com** & **Redfin** simultaneously
|
||||
- Aggregates the properties in a Pandas DataFrame
|
||||
|
||||
|
||||
[Video Guide for HomeHarvest](https://www.youtube.com/watch?v=HCoHoiJdWQY)
|
||||
|
||||
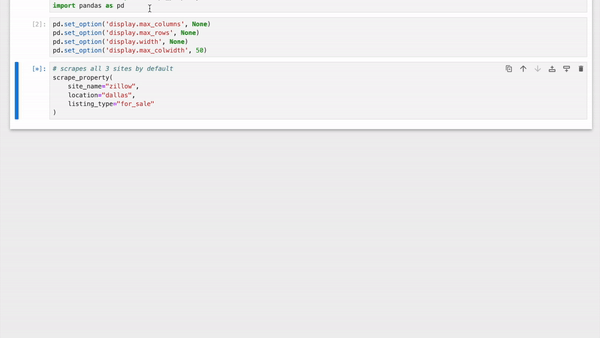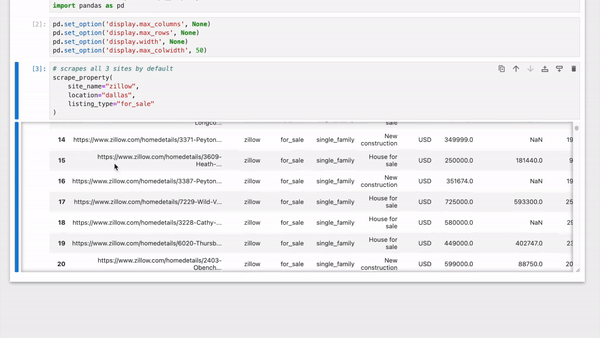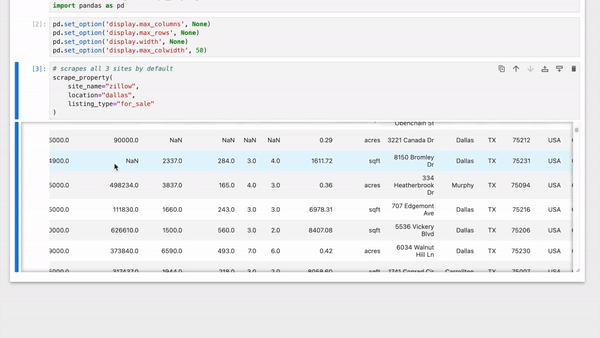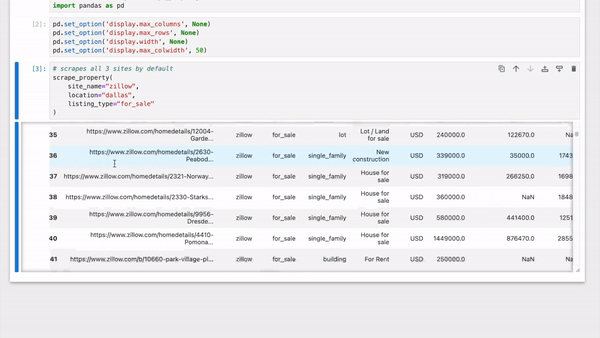
|
||||
|
||||
## Installation
|
||||
|
||||
```bash
|
||||
pip install --upgrade homeharvest
|
||||
pip install homeharvest
|
||||
```
|
||||
_Python version >= [3.10](https://www.python.org/downloads/release/python-3100/) required_
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
### CLI
|
||||
|
||||
```bash
|
||||
homeharvest "San Francisco, CA" -s zillow realtor.com redfin -l for_rent -o excel -f HomeHarvest
|
||||
```
|
||||
|
||||
This will scrape properties from the specified sites for the given location and listing type, and save the results to an Excel file named `HomeHarvest.xlsx`.
|
||||
|
||||
By default:
|
||||
- If `-s` or `--site_name` is not provided, it will scrape from all available sites.
|
||||
- If `-l` or `--listing_type` is left blank, the default is `for_sale`. Other options are `for_rent` or `sold`.
|
||||
- The `-o` or `--output` default format is `excel`. Options are `csv` or `excel`.
|
||||
- If `-f` or `--filename` is left blank, the default is `HomeHarvest_<current_timestamp>`.
|
||||
- If `-p` or `--proxy` is not provided, the scraper uses the local IP.
|
||||
### Python
|
||||
|
||||
```py
|
||||
from homeharvest import scrape_property
|
||||
import pandas as pd
|
||||
@@ -33,16 +52,17 @@ properties: pd.DataFrame = scrape_property(
|
||||
#: Note, to export to CSV or Excel, use properties.to_csv() or properties.to_excel().
|
||||
print(properties)
|
||||
```
|
||||
|
||||
## Output
|
||||
```py
|
||||
>>> properties.head()
|
||||
street city ... mls_id description
|
||||
0 420 N Scottsdale Rd Tempe ... NaN NaN
|
||||
1 1255 E University Dr Tempe ... NaN NaN
|
||||
2 1979 E Rio Salado Pkwy Tempe ... NaN NaN
|
||||
3 548 S Wilson St Tempe ... None None
|
||||
4 945 E Playa Del Norte Dr Unit 4027 Tempe ... NaN NaN
|
||||
[5 rows x 23 columns]
|
||||
property_url site_name listing_type apt_min_price apt_max_price ...
|
||||
0 https://www.redfin.com/AZ/Tempe/1003-W-Washing... redfin for_rent 1666.0 2750.0 ...
|
||||
1 https://www.redfin.com/AZ/Tempe/VELA-at-Town-L... redfin for_rent 1665.0 3763.0 ...
|
||||
2 https://www.redfin.com/AZ/Tempe/Camden-Tempe/a... redfin for_rent 1939.0 3109.0 ...
|
||||
3 https://www.redfin.com/AZ/Tempe/Emerson-Park/a... redfin for_rent 1185.0 1817.0 ...
|
||||
4 https://www.redfin.com/AZ/Tempe/Rio-Paradiso-A... redfin for_rent 1470.0 2235.0 ...
|
||||
[5 rows x 41 columns]
|
||||
```
|
||||
|
||||
### Parameters for `scrape_properties()`
|
||||
@@ -52,6 +72,7 @@ Required
|
||||
└── listing_type (enum): for_rent, for_sale, sold
|
||||
Optional
|
||||
├── site_name (List[enum], default=all three sites): zillow, realtor.com, redfin
|
||||
├── proxy (str): in format 'http://user:pass@host:port' or [https, socks]
|
||||
```
|
||||
|
||||
### Property Schema
|
||||
@@ -102,7 +123,14 @@ Property
|
||||
│ └── bldg_min_area (int)
|
||||
|
||||
└── Apartment Details (for property type: apartment):
|
||||
└── apt_min_price (int)
|
||||
├── apt_min_beds: int
|
||||
├── apt_max_beds: int
|
||||
├── apt_min_baths: float
|
||||
├── apt_max_baths: float
|
||||
├── apt_min_price: int
|
||||
├── apt_max_price: int
|
||||
├── apt_min_sqft: int
|
||||
├── apt_max_sqft: int
|
||||
```
|
||||
## Supported Countries for Property Scraping
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ _scrapers = {
|
||||
}
|
||||
|
||||
|
||||
def validate_input(site_name: str, listing_type: str) -> None:
|
||||
def _validate_input(site_name: str, listing_type: str) -> None:
|
||||
if site_name.lower() not in _scrapers:
|
||||
raise InvalidSite(f"Provided site, '{site_name}', does not exist.")
|
||||
|
||||
@@ -28,7 +28,7 @@ def validate_input(site_name: str, listing_type: str) -> None:
|
||||
)
|
||||
|
||||
|
||||
def get_ordered_properties(result: Property) -> list[str]:
|
||||
def _get_ordered_properties(result: Property) -> list[str]:
|
||||
return [
|
||||
"property_url",
|
||||
"site_name",
|
||||
@@ -38,6 +38,13 @@ def get_ordered_properties(result: Property) -> list[str]:
|
||||
"currency",
|
||||
"price",
|
||||
"apt_min_price",
|
||||
"apt_max_price",
|
||||
"apt_min_sqft",
|
||||
"apt_max_sqft",
|
||||
"apt_min_beds",
|
||||
"apt_max_beds",
|
||||
"apt_min_baths",
|
||||
"apt_max_baths",
|
||||
"tax_assessed_value",
|
||||
"square_feet",
|
||||
"price_per_sqft",
|
||||
@@ -61,14 +68,14 @@ def get_ordered_properties(result: Property) -> list[str]:
|
||||
"year_built",
|
||||
"agent_name",
|
||||
"mls_id",
|
||||
"description",
|
||||
"img_src",
|
||||
"latitude",
|
||||
"longitude",
|
||||
"description",
|
||||
]
|
||||
|
||||
|
||||
def process_result(result: Property) -> pd.DataFrame:
|
||||
def _process_result(result: Property) -> pd.DataFrame:
|
||||
prop_data = result.__dict__
|
||||
|
||||
prop_data["site_name"] = prop_data["site_name"].value
|
||||
@@ -89,29 +96,30 @@ def process_result(result: Property) -> pd.DataFrame:
|
||||
del prop_data["address"]
|
||||
|
||||
properties_df = pd.DataFrame([prop_data])
|
||||
properties_df = properties_df[get_ordered_properties(result)]
|
||||
properties_df = properties_df[_get_ordered_properties(result)]
|
||||
|
||||
return properties_df
|
||||
|
||||
|
||||
def _scrape_single_site(
|
||||
location: str, site_name: str, listing_type: str
|
||||
location: str, site_name: str, listing_type: str, proxy: str = None
|
||||
) -> pd.DataFrame:
|
||||
"""
|
||||
Helper function to scrape a single site.
|
||||
"""
|
||||
validate_input(site_name, listing_type)
|
||||
_validate_input(site_name, listing_type)
|
||||
|
||||
scraper_input = ScraperInput(
|
||||
location=location,
|
||||
listing_type=ListingType[listing_type.upper()],
|
||||
site_name=SiteName.get_by_value(site_name.lower()),
|
||||
proxy=proxy,
|
||||
)
|
||||
|
||||
site = _scrapers[site_name.lower()](scraper_input)
|
||||
results = site.search()
|
||||
|
||||
properties_dfs = [process_result(result) for result in results]
|
||||
properties_dfs = [_process_result(result) for result in results]
|
||||
properties_dfs = [
|
||||
df.dropna(axis=1, how="all") for df in properties_dfs if not df.empty
|
||||
]
|
||||
@@ -125,6 +133,7 @@ def scrape_property(
|
||||
location: str,
|
||||
site_name: Union[str, list[str]] = None,
|
||||
listing_type: str = "for_sale",
|
||||
proxy: str = None,
|
||||
) -> pd.DataFrame:
|
||||
"""
|
||||
Scrape property from various sites from a given location and listing type.
|
||||
@@ -144,13 +153,13 @@ def scrape_property(
|
||||
results = []
|
||||
|
||||
if len(site_name) == 1:
|
||||
final_df = _scrape_single_site(location, site_name[0], listing_type)
|
||||
final_df = _scrape_single_site(location, site_name[0], listing_type, proxy)
|
||||
results.append(final_df)
|
||||
else:
|
||||
with ThreadPoolExecutor() as executor:
|
||||
futures = {
|
||||
executor.submit(
|
||||
_scrape_single_site, location, s_name, listing_type
|
||||
_scrape_single_site, location, s_name, listing_type, proxy
|
||||
): s_name
|
||||
for s_name in site_name
|
||||
}
|
||||
|
||||
72
homeharvest/cli.py
Normal file
72
homeharvest/cli.py
Normal file
@@ -0,0 +1,72 @@
|
||||
import argparse
|
||||
import datetime
|
||||
from homeharvest import scrape_property
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(description="Home Harvest Property Scraper")
|
||||
parser.add_argument(
|
||||
"location", type=str, help="Location to scrape (e.g., San Francisco, CA)"
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-s",
|
||||
"--site_name",
|
||||
type=str,
|
||||
nargs="*",
|
||||
default=None,
|
||||
help="Site name(s) to scrape from (e.g., realtor, zillow)",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-l",
|
||||
"--listing_type",
|
||||
type=str,
|
||||
default="for_sale",
|
||||
choices=["for_sale", "for_rent", "sold"],
|
||||
help="Listing type to scrape",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-o",
|
||||
"--output",
|
||||
type=str,
|
||||
default="excel",
|
||||
choices=["excel", "csv"],
|
||||
help="Output format",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-f",
|
||||
"--filename",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Name of the output file (without extension)",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-p", "--proxy", type=str, default=None, help="Proxy to use for scraping"
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
result = scrape_property(
|
||||
args.location, args.site_name, args.listing_type, proxy=args.proxy
|
||||
)
|
||||
|
||||
if not args.filename:
|
||||
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
args.filename = f"HomeHarvest_{timestamp}"
|
||||
|
||||
if args.output == "excel":
|
||||
output_filename = f"{args.filename}.xlsx"
|
||||
result.to_excel(output_filename, index=False)
|
||||
print(f"Excel file saved as {output_filename}")
|
||||
elif args.output == "csv":
|
||||
output_filename = f"{args.filename}.csv"
|
||||
result.to_csv(output_filename, index=False)
|
||||
print(f"CSV file saved as {output_filename}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -8,7 +8,7 @@ class ScraperInput:
|
||||
location: str
|
||||
listing_type: ListingType
|
||||
site_name: SiteName
|
||||
proxy_url: str | None = None
|
||||
proxy: str | None = None
|
||||
|
||||
|
||||
class Scraper:
|
||||
@@ -17,15 +17,16 @@ class Scraper:
|
||||
self.listing_type = scraper_input.listing_type
|
||||
|
||||
self.session = requests.Session()
|
||||
if scraper_input.proxy:
|
||||
proxy_url = scraper_input.proxy
|
||||
proxies = {
|
||||
"http": proxy_url,
|
||||
"https": proxy_url
|
||||
}
|
||||
self.session.proxies.update(proxies)
|
||||
self.listing_type = scraper_input.listing_type
|
||||
self.site_name = scraper_input.site_name
|
||||
|
||||
if scraper_input.proxy_url:
|
||||
self.session.proxies = {
|
||||
"http": scraper_input.proxy_url,
|
||||
"https": scraper_input.proxy_url,
|
||||
}
|
||||
|
||||
def search(self) -> list[Property]:
|
||||
...
|
||||
|
||||
|
||||
@@ -102,4 +102,11 @@ class Property:
|
||||
bldg_min_area: int | None = None
|
||||
|
||||
# apt
|
||||
apt_min_beds: int | None = None
|
||||
apt_max_beds: int | None = None
|
||||
apt_min_baths: float | None = None
|
||||
apt_max_baths: float | None = None
|
||||
apt_min_price: int | None = None
|
||||
apt_max_price: int | None = None
|
||||
apt_min_sqft: int | None = None
|
||||
apt_max_sqft: int | None = None
|
||||
|
||||
@@ -2,7 +2,7 @@ import json
|
||||
from typing import Any
|
||||
from .. import Scraper
|
||||
from ....utils import parse_address_two, parse_unit
|
||||
from ..models import Property, Address, PropertyType
|
||||
from ..models import Property, Address, PropertyType, ListingType, SiteName
|
||||
from ....exceptions import NoResultsFound
|
||||
|
||||
|
||||
@@ -49,21 +49,21 @@ class RedfinScraper(Scraper):
|
||||
unit = parse_unit(get_value("streetLine"))
|
||||
address = Address(
|
||||
street_address=street_address,
|
||||
city=home["city"],
|
||||
state=home["state"],
|
||||
zip_code=home["zip"],
|
||||
city=home.get("city"),
|
||||
state=home.get("state"),
|
||||
zip_code=home.get("zip"),
|
||||
unit=unit,
|
||||
country="USA",
|
||||
)
|
||||
else:
|
||||
address_info = home["streetAddress"]
|
||||
street_address, unit = parse_address_two(address_info["assembledAddress"])
|
||||
address_info = home.get("streetAddress")
|
||||
street_address, unit = parse_address_two(address_info.get("assembledAddress"))
|
||||
|
||||
address = Address(
|
||||
street_address=street_address,
|
||||
city=home["city"],
|
||||
state=home["state"],
|
||||
zip_code=home["zip"],
|
||||
city=home.get("city"),
|
||||
state=home.get("state"),
|
||||
zip_code=home.get("zip"),
|
||||
unit=unit,
|
||||
country="USA",
|
||||
)
|
||||
@@ -108,6 +108,64 @@ class RedfinScraper(Scraper):
|
||||
else None,
|
||||
)
|
||||
|
||||
def _handle_rentals(self, region_id, region_type):
|
||||
url = f"https://www.redfin.com/stingray/api/v1/search/rentals?al=1&isRentals=true®ion_id={region_id}®ion_type={region_type}&num_homes=100000"
|
||||
|
||||
response = self.session.get(url)
|
||||
response.raise_for_status()
|
||||
homes = response.json()
|
||||
|
||||
properties_list = []
|
||||
|
||||
for home in homes["homes"]:
|
||||
home_data = home["homeData"]
|
||||
rental_data = home["rentalExtension"]
|
||||
|
||||
property_url = f"https://www.redfin.com{home_data.get('url', '')}"
|
||||
address_info = home_data.get("addressInfo", {})
|
||||
centroid = address_info.get("centroid", {}).get("centroid", {})
|
||||
address = Address(
|
||||
street_address=address_info.get("formattedStreetLine", None),
|
||||
city=address_info.get("city", None),
|
||||
state=address_info.get("state", None),
|
||||
zip_code=address_info.get("zip", None),
|
||||
unit=None,
|
||||
country="US" if address_info.get("countryCode", None) == 1 else None,
|
||||
)
|
||||
|
||||
price_range = rental_data.get("rentPriceRange", {"min": None, "max": None})
|
||||
bed_range = rental_data.get("bedRange", {"min": None, "max": None})
|
||||
bath_range = rental_data.get("bathRange", {"min": None, "max": None})
|
||||
sqft_range = rental_data.get("sqftRange", {"min": None, "max": None})
|
||||
|
||||
property_ = Property(
|
||||
property_url=property_url,
|
||||
site_name=SiteName.REDFIN,
|
||||
listing_type=ListingType.FOR_RENT,
|
||||
address=address,
|
||||
apt_min_beds=bed_range.get("min", None),
|
||||
apt_min_baths=bath_range.get("min", None),
|
||||
apt_max_beds=bed_range.get("max", None),
|
||||
apt_max_baths=bath_range.get("max", None),
|
||||
description=rental_data.get("description", None),
|
||||
latitude=centroid.get("latitude", None),
|
||||
longitude=centroid.get("longitude", None),
|
||||
apt_min_price=price_range.get("min", None),
|
||||
apt_max_price=price_range.get("max", None),
|
||||
apt_min_sqft=sqft_range.get("min", None),
|
||||
apt_max_sqft=sqft_range.get("max", None),
|
||||
img_src=home_data.get("staticMapUrl", None),
|
||||
posted_time=rental_data.get("lastUpdated", None),
|
||||
bldg_name=rental_data.get("propertyName", None),
|
||||
)
|
||||
|
||||
properties_list.append(property_)
|
||||
|
||||
if not properties_list:
|
||||
raise NoResultsFound("No rentals found for the given location.")
|
||||
|
||||
return properties_list
|
||||
|
||||
def _parse_building(self, building: dict) -> Property:
|
||||
street_address = " ".join(
|
||||
[
|
||||
@@ -168,18 +226,19 @@ class RedfinScraper(Scraper):
|
||||
home_id = region_id
|
||||
return self.handle_address(home_id)
|
||||
|
||||
url = "https://www.redfin.com/stingray/api/gis?al=1®ion_id={}®ion_type={}".format(
|
||||
region_id, region_type
|
||||
)
|
||||
|
||||
response = self.session.get(url)
|
||||
response_json = json.loads(response.text.replace("{}&&", ""))
|
||||
|
||||
homes = [
|
||||
self._parse_home(home) for home in response_json["payload"]["homes"]
|
||||
] + [
|
||||
self._parse_building(building)
|
||||
for building in response_json["payload"]["buildings"].values()
|
||||
]
|
||||
|
||||
return homes
|
||||
if self.listing_type == ListingType.FOR_RENT:
|
||||
return self._handle_rentals(region_id, region_type)
|
||||
else:
|
||||
if self.listing_type == ListingType.FOR_SALE:
|
||||
url = f"https://www.redfin.com/stingray/api/gis?al=1®ion_id={region_id}®ion_type={region_type}&num_homes=100000"
|
||||
else:
|
||||
url = f"https://www.redfin.com/stingray/api/gis?al=1®ion_id={region_id}®ion_type={region_type}&sold_within_days=30&num_homes=100000"
|
||||
response = self.session.get(url)
|
||||
response_json = json.loads(response.text.replace("{}&&", ""))
|
||||
homes = [
|
||||
self._parse_home(home) for home in response_json["payload"]["homes"]
|
||||
] + [
|
||||
self._parse_building(building)
|
||||
for building in response_json["payload"]["buildings"].values()
|
||||
]
|
||||
return homes
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
import re
|
||||
import json
|
||||
import string
|
||||
from .. import Scraper
|
||||
from ....utils import parse_address_two, parse_unit
|
||||
from ....exceptions import GeoCoordsNotFound, NoResultsFound
|
||||
@@ -10,9 +9,10 @@ from ..models import Property, Address, ListingType, PropertyType
|
||||
class ZillowScraper(Scraper):
|
||||
def __init__(self, scraper_input):
|
||||
super().__init__(scraper_input)
|
||||
self.listing_type = scraper_input.listing_type
|
||||
|
||||
if not self.is_plausible_location(self.location):
|
||||
raise NoResultsFound("Invalid location input: {}".format(self.location))
|
||||
|
||||
if self.listing_type == ListingType.FOR_SALE:
|
||||
self.url = f"https://www.zillow.com/homes/for_sale/{self.location}_rb/"
|
||||
elif self.listing_type == ListingType.FOR_RENT:
|
||||
@@ -20,20 +20,20 @@ class ZillowScraper(Scraper):
|
||||
else:
|
||||
self.url = f"https://www.zillow.com/homes/recently_sold/{self.location}_rb/"
|
||||
|
||||
@staticmethod
|
||||
def is_plausible_location(location: str) -> bool:
|
||||
blocks = location.split()
|
||||
for block in blocks:
|
||||
if (
|
||||
any(char.isdigit() for char in block)
|
||||
and any(char.isalpha() for char in block)
|
||||
and len(block) > 6
|
||||
):
|
||||
return False
|
||||
return True
|
||||
def is_plausible_location(self, location: str) -> bool:
|
||||
url = (
|
||||
"https://www.zillowstatic.com/autocomplete/v3/suggestions?q={"
|
||||
"}&abKey=6666272a-4b99-474c-b857-110ec438732b&clientId=homepage-render"
|
||||
).format(location)
|
||||
|
||||
response = self.session.get(url)
|
||||
|
||||
return response.json()["results"] != []
|
||||
|
||||
def search(self):
|
||||
resp = self.session.get(self.url, headers=self._get_headers())
|
||||
resp = self.session.get(
|
||||
self.url, headers=self._get_headers()
|
||||
)
|
||||
resp.raise_for_status()
|
||||
content = resp.text
|
||||
|
||||
@@ -130,7 +130,9 @@ class ZillowScraper(Scraper):
|
||||
"wants": {"cat1": ["mapResults"]},
|
||||
"isDebugRequest": False,
|
||||
}
|
||||
resp = self.session.put(url, headers=self._get_headers(), json=payload)
|
||||
resp = self.session.put(
|
||||
url, headers=self._get_headers(), json=payload
|
||||
)
|
||||
resp.raise_for_status()
|
||||
a = resp.json()
|
||||
return self._parse_properties(resp.json())
|
||||
@@ -189,7 +191,9 @@ class ZillowScraper(Scraper):
|
||||
else None,
|
||||
"img_src": result.get("imgSrc"),
|
||||
"price_per_sqft": int(home_info["price"] // home_info["livingArea"])
|
||||
if "livingArea" in home_info and "price" in home_info
|
||||
if "livingArea" in home_info
|
||||
and home_info["livingArea"] != 0
|
||||
and "price" in home_info
|
||||
else None,
|
||||
}
|
||||
property_obj = Property(**property_data)
|
||||
|
||||
27
poetry.lock
generated
27
poetry.lock
generated
@@ -106,6 +106,17 @@ files = [
|
||||
{file = "colorama-0.4.6.tar.gz", hash = "sha256:08695f5cb7ed6e0531a20572697297273c47b8cae5a63ffc6d6ed5c201be6e44"},
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "et-xmlfile"
|
||||
version = "1.1.0"
|
||||
description = "An implementation of lxml.xmlfile for the standard library"
|
||||
optional = false
|
||||
python-versions = ">=3.6"
|
||||
files = [
|
||||
{file = "et_xmlfile-1.1.0-py3-none-any.whl", hash = "sha256:a2ba85d1d6a74ef63837eed693bcb89c3f752169b0e3e7ae5b16ca5e1b3deada"},
|
||||
{file = "et_xmlfile-1.1.0.tar.gz", hash = "sha256:8eb9e2bc2f8c97e37a2dc85a09ecdcdec9d8a396530a6d5a33b30b9a92da0c5c"},
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "exceptiongroup"
|
||||
version = "1.1.3"
|
||||
@@ -217,6 +228,20 @@ files = [
|
||||
{file = "numpy-1.26.0.tar.gz", hash = "sha256:f93fc78fe8bf15afe2b8d6b6499f1c73953169fad1e9a8dd086cdff3190e7fdf"},
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "openpyxl"
|
||||
version = "3.1.2"
|
||||
description = "A Python library to read/write Excel 2010 xlsx/xlsm files"
|
||||
optional = false
|
||||
python-versions = ">=3.6"
|
||||
files = [
|
||||
{file = "openpyxl-3.1.2-py2.py3-none-any.whl", hash = "sha256:f91456ead12ab3c6c2e9491cf33ba6d08357d802192379bb482f1033ade496f5"},
|
||||
{file = "openpyxl-3.1.2.tar.gz", hash = "sha256:a6f5977418eff3b2d5500d54d9db50c8277a368436f4e4f8ddb1be3422870184"},
|
||||
]
|
||||
|
||||
[package.dependencies]
|
||||
et-xmlfile = "*"
|
||||
|
||||
[[package]]
|
||||
name = "packaging"
|
||||
version = "23.1"
|
||||
@@ -425,4 +450,4 @@ zstd = ["zstandard (>=0.18.0)"]
|
||||
[metadata]
|
||||
lock-version = "2.0"
|
||||
python-versions = "^3.10"
|
||||
content-hash = "eede625d6d45085e143b0af246cb2ce00cff8579c667be3b63387c8594a5570d"
|
||||
content-hash = "3647d568f5623dd762f19029230626a62e68309fa2ef8be49a36382c19264a5f"
|
||||
|
||||
@@ -1,15 +1,19 @@
|
||||
[tool.poetry]
|
||||
name = "homeharvest"
|
||||
version = "0.2.1"
|
||||
version = "0.2.6"
|
||||
description = "Real estate scraping library supporting Zillow, Realtor.com & Redfin."
|
||||
authors = ["Zachary Hampton <zachary@zacharysproducts.com>", "Cullen Watson <cullen@cullen.ai>"]
|
||||
homepage = "https://github.com/ZacharyHampton/HomeHarvest"
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.scripts]
|
||||
homeharvest = "homeharvest.cli:main"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.10"
|
||||
requests = "^2.31.0"
|
||||
pandas = "^2.1.0"
|
||||
openpyxl = "^3.1.2"
|
||||
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
|
||||
Reference in New Issue
Block a user