mirror of
https://github.com/Bunsly/HomeHarvest.git
synced 2026-03-05 12:04:31 -08:00
Compare commits
58 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
93a1cbe17f | ||
|
|
49d27943c4 | ||
|
|
05fca9b7e6 | ||
|
|
20ce44fb3a | ||
|
|
52017c1bb5 | ||
|
|
dba1c03081 | ||
|
|
1fc2d8c549 | ||
|
|
02d112eea0 | ||
|
|
30e510882b | ||
|
|
78b56c2cac | ||
|
|
087854a688 | ||
|
|
80586467a8 | ||
|
|
3494b152b8 | ||
|
|
6c6fef80ed | ||
|
|
62e3321277 | ||
|
|
80186ee8c5 | ||
|
|
3ec47c5b6a | ||
|
|
42e8ac4de9 | ||
|
|
e1917009ae | ||
|
|
7297f0eb33 | ||
|
|
2eec389838 | ||
|
|
b01162161d | ||
|
|
906ce92685 | ||
|
|
cc76e067b2 | ||
|
|
1f0c351974 | ||
|
|
a1684f87db | ||
|
|
2ae3ebe28e | ||
|
|
ae3961514b | ||
|
|
0621b01d9a | ||
|
|
fbbd56d930 | ||
|
|
82092faa28 | ||
|
|
8f90a80b0a | ||
|
|
d5b4d80f96 | ||
|
|
086bcfd224 | ||
|
|
4726764482 | ||
|
|
ca260fd2b4 | ||
|
|
94e5b090da | ||
|
|
d0a6a66b6a | ||
|
|
8e140a0e45 | ||
|
|
588689c230 | ||
|
|
c7a4bfd5e4 | ||
|
|
fe351ab57c | ||
|
|
5d0f519a85 | ||
|
|
869d7e7c51 | ||
|
|
ffd3ce6aed | ||
|
|
471e53118e | ||
|
|
dc8c15959f | ||
|
|
10c01f373e | ||
|
|
fd01bfb8b8 | ||
|
|
c3c6bdd2c5 | ||
|
|
29897b8fbe | ||
|
|
54af03c86a | ||
|
|
6b02394e95 | ||
|
|
ba249ca20d | ||
|
|
ba9fe806a7 | ||
|
|
905cfcae2c | ||
|
|
3697b7cf2d | ||
|
|
b76c659f94 |
2
.gitignore
vendored
2
.gitignore
vendored
@@ -3,3 +3,5 @@
|
|||||||
**/__pycache__/
|
**/__pycache__/
|
||||||
**/.pytest_cache/
|
**/.pytest_cache/
|
||||||
*.pyc
|
*.pyc
|
||||||
|
/.ipynb_checkpoints/
|
||||||
|
*.csv
|
||||||
118
HomeHarvest_Demo.ipynb
Normal file
118
HomeHarvest_Demo.ipynb
Normal file
@@ -0,0 +1,118 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "cb48903e-5021-49fe-9688-45cd0bc05d0f",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from homeharvest import scrape_property\n",
|
||||||
|
"import pandas as pd"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "156488ce-0d5f-43c5-87f4-c33e9c427860",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"pd.set_option('display.max_columns', None) # Show all columns\n",
|
||||||
|
"pd.set_option('display.max_rows', None) # Show all rows\n",
|
||||||
|
"pd.set_option('display.width', None) # Auto-adjust display width to fit console\n",
|
||||||
|
"pd.set_option('display.max_colwidth', 50) # Limit max column width to 50 characters"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "1c8b9744-8606-4e9b-8add-b90371a249a7",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# scrapes all 3 sites by default\n",
|
||||||
|
"scrape_property(\n",
|
||||||
|
" location=\"dallas\",\n",
|
||||||
|
" listing_type=\"for_sale\"\n",
|
||||||
|
")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "aaf86093",
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"jupyter": {
|
||||||
|
"outputs_hidden": false
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# search a specific address\n",
|
||||||
|
"scrape_property(\n",
|
||||||
|
" location=\"2530 Al Lipscomb Way\",\n",
|
||||||
|
" site_name=\"zillow\",\n",
|
||||||
|
" listing_type=\"for_sale\"\n",
|
||||||
|
")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "ab7b4c21-da1d-4713-9df4-d7425d8ce21e",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# check rentals\n",
|
||||||
|
"scrape_property(\n",
|
||||||
|
" location=\"chicago, illinois\",\n",
|
||||||
|
" site_name=[\"redfin\", \"zillow\"],\n",
|
||||||
|
" listing_type=\"for_rent\"\n",
|
||||||
|
")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "af280cd3",
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"jupyter": {
|
||||||
|
"outputs_hidden": false
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# check sold properties\n",
|
||||||
|
"scrape_property(\n",
|
||||||
|
" location=\"90210\",\n",
|
||||||
|
" site_name=[\"redfin\"],\n",
|
||||||
|
" listing_type=\"sold\"\n",
|
||||||
|
")"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3 (ipykernel)",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python3"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.10.11"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 5
|
||||||
|
}
|
||||||
166
README.md
166
README.md
@@ -1,35 +1,163 @@
|
|||||||
# HomeHarvest
|
<img src="https://github.com/ZacharyHampton/HomeHarvest/assets/78247585/d1a2bf8b-09f5-4c57-b33a-0ada8a34f12d" width="400">
|
||||||
|
|
||||||
**HomeHarvest** aims to be the top Python real estate scraping library.
|
**HomeHarvest** is a simple, yet comprehensive, real estate scraping library.
|
||||||
|
|
||||||
## RoadMap
|
[](https://replit.com/@ZacharyHampton/HomeHarvestDemo)
|
||||||
|
|
||||||
- **Supported Sites**: Currently, we support scraping from sites such as `Zillow` and `RedFin`.
|
*Looking to build a data-focused software product?* **[Book a call](https://calendly.com/zachary-products/15min)** *to work with us.*
|
||||||
- **Output**: Provides the option to return the scraped data as a Pandas dataframe.
|
## Features
|
||||||
- **Under Consideration**: We're looking into the possibility of an Excel plugin to cater to a broader audience.
|
|
||||||
|
|
||||||
## Site Name Options
|
- Scrapes properties from **Zillow**, **Realtor.com** & **Redfin** simultaneously
|
||||||
|
- Aggregates the properties in a Pandas DataFrame
|
||||||
|
|
||||||
- `zillow`
|
[Video Guide for HomeHarvest](https://www.youtube.com/watch?v=HCoHoiJdWQY)
|
||||||
- `redfin`
|
|
||||||
|
|
||||||
## Listing Types
|
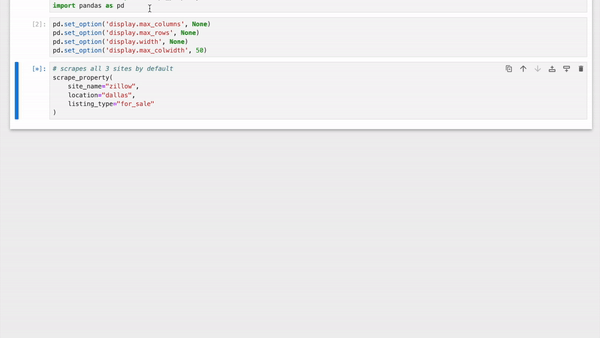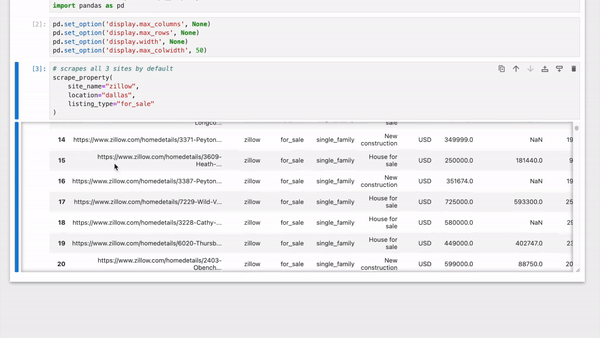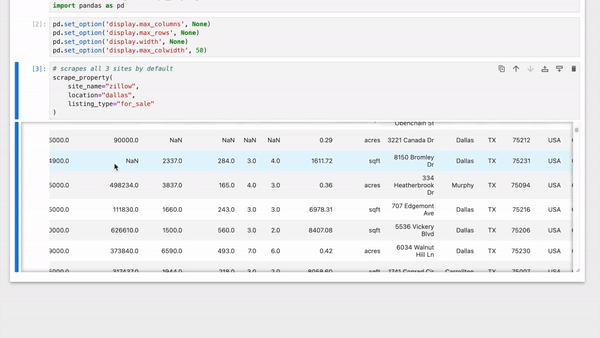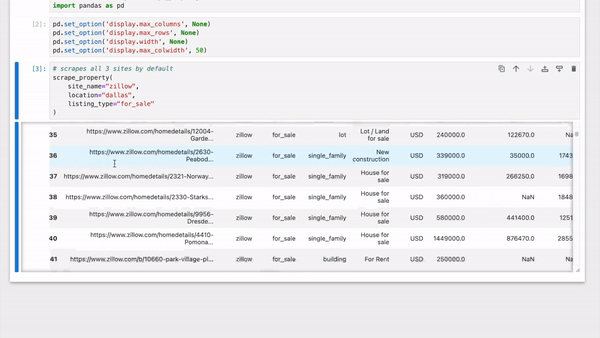
|
||||||
|
|
||||||
- `for_rent`
|
## Installation
|
||||||
- `for_sale`
|
|
||||||
|
|
||||||
### Installation
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
pip install --upgrade homeharvest
|
pip install --force-reinstall homeharvest
|
||||||
|
```
|
||||||
|
_Python version >= [3.10](https://www.python.org/downloads/release/python-3100/) required_
|
||||||
|
|
||||||
|
## Usage
|
||||||
|
|
||||||
|
### CLI
|
||||||
|
|
||||||
|
```bash
|
||||||
|
homeharvest "San Francisco, CA" --site_name zillow realtor.com redfin --listing_type for_rent --output excel --filename HomeHarvest
|
||||||
```
|
```
|
||||||
|
|
||||||
### Example Usage
|
This will scrape properties from the specified sites for the given location and listing type, and save the results to an Excel file named `HomeHarvest.xlsx`.
|
||||||
```
|
|
||||||
|
By default:
|
||||||
|
- If `--site_name` is not provided, it will scrape from all available sites.
|
||||||
|
- If `--listing_type` is left blank, the default is `for_sale`, other options are `for_rent` or `sold`.
|
||||||
|
- The `--output` default format is `excel`, options are `csv` or `excel`.
|
||||||
|
- If `--filename` is left blank, the default is `HomeHarvest_<current_timestamp>`
|
||||||
|
|
||||||
|
### Python
|
||||||
|
```py
|
||||||
from homeharvest import scrape_property
|
from homeharvest import scrape_property
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
properties = scrape_property(
|
properties: pd.DataFrame = scrape_property(
|
||||||
location="85281", site_name="zillow", listing_type="for_rent"
|
site_name=["zillow", "realtor.com", "redfin"],
|
||||||
|
location="85281",
|
||||||
|
listing_type="for_rent" # for_sale / sold
|
||||||
)
|
)
|
||||||
|
|
||||||
|
#: Note, to export to CSV or Excel, use properties.to_csv() or properties.to_excel().
|
||||||
print(properties)
|
print(properties)
|
||||||
```
|
```
|
||||||
|
|
||||||
|
## Output
|
||||||
|
```py
|
||||||
|
>>> properties.head()
|
||||||
|
property_url site_name listing_type apt_min_price apt_max_price ...
|
||||||
|
0 https://www.redfin.com/AZ/Tempe/1003-W-Washing... redfin for_rent 1666.0 2750.0 ...
|
||||||
|
1 https://www.redfin.com/AZ/Tempe/VELA-at-Town-L... redfin for_rent 1665.0 3763.0 ...
|
||||||
|
2 https://www.redfin.com/AZ/Tempe/Camden-Tempe/a... redfin for_rent 1939.0 3109.0 ...
|
||||||
|
3 https://www.redfin.com/AZ/Tempe/Emerson-Park/a... redfin for_rent 1185.0 1817.0 ...
|
||||||
|
4 https://www.redfin.com/AZ/Tempe/Rio-Paradiso-A... redfin for_rent 1470.0 2235.0 ...
|
||||||
|
[5 rows x 41 columns]
|
||||||
|
```
|
||||||
|
|
||||||
|
### Parameters for `scrape_properties()`
|
||||||
|
```plaintext
|
||||||
|
Required
|
||||||
|
├── location (str): address in various formats e.g. just zip, full address, city/state, etc.
|
||||||
|
└── listing_type (enum): for_rent, for_sale, sold
|
||||||
|
Optional
|
||||||
|
├── site_name (List[enum], default=all three sites): zillow, realtor.com, redfin
|
||||||
|
```
|
||||||
|
|
||||||
|
### Property Schema
|
||||||
|
```plaintext
|
||||||
|
Property
|
||||||
|
├── Basic Information:
|
||||||
|
│ ├── property_url (str)
|
||||||
|
│ ├── site_name (enum): zillow, redfin, realtor.com
|
||||||
|
│ ├── listing_type (enum: ListingType)
|
||||||
|
│ └── property_type (enum): house, apartment, condo, townhouse, single_family, multi_family, building
|
||||||
|
|
||||||
|
├── Address Details:
|
||||||
|
│ ├── street_address (str)
|
||||||
|
│ ├── city (str)
|
||||||
|
│ ├── state (str)
|
||||||
|
│ ├── zip_code (str)
|
||||||
|
│ ├── unit (str)
|
||||||
|
│ └── country (str)
|
||||||
|
|
||||||
|
├── Property Features:
|
||||||
|
│ ├── price (int)
|
||||||
|
│ ├── tax_assessed_value (int)
|
||||||
|
│ ├── currency (str)
|
||||||
|
│ ├── square_feet (int)
|
||||||
|
│ ├── beds (int)
|
||||||
|
│ ├── baths (float)
|
||||||
|
│ ├── lot_area_value (float)
|
||||||
|
│ ├── lot_area_unit (str)
|
||||||
|
│ ├── stories (int)
|
||||||
|
│ └── year_built (int)
|
||||||
|
|
||||||
|
├── Miscellaneous Details:
|
||||||
|
│ ├── price_per_sqft (int)
|
||||||
|
│ ├── mls_id (str)
|
||||||
|
│ ├── agent_name (str)
|
||||||
|
│ ├── img_src (str)
|
||||||
|
│ ├── description (str)
|
||||||
|
│ ├── status_text (str)
|
||||||
|
│ ├── latitude (float)
|
||||||
|
│ ├── longitude (float)
|
||||||
|
│ └── posted_time (str) [Only for Zillow]
|
||||||
|
|
||||||
|
├── Building Details (for property_type: building):
|
||||||
|
│ ├── bldg_name (str)
|
||||||
|
│ ├── bldg_unit_count (int)
|
||||||
|
│ ├── bldg_min_beds (int)
|
||||||
|
│ ├── bldg_min_baths (float)
|
||||||
|
│ └── bldg_min_area (int)
|
||||||
|
|
||||||
|
└── Apartment Details (for property type: apartment):
|
||||||
|
├── apt_min_beds: int
|
||||||
|
├── apt_max_beds: int
|
||||||
|
├── apt_min_baths: float
|
||||||
|
├── apt_max_baths: float
|
||||||
|
├── apt_min_price: int
|
||||||
|
├── apt_max_price: int
|
||||||
|
├── apt_min_sqft: int
|
||||||
|
├── apt_max_sqft: int
|
||||||
|
```
|
||||||
|
## Supported Countries for Property Scraping
|
||||||
|
|
||||||
|
* **Zillow**: contains listings in the **US** & **Canada**
|
||||||
|
* **Realtor.com**: mainly from the **US** but also has international listings
|
||||||
|
* **Redfin**: listings mainly in the **US**, **Canada**, & has expanded to some areas in **Mexico**
|
||||||
|
|
||||||
|
### Exceptions
|
||||||
|
The following exceptions may be raised when using HomeHarvest:
|
||||||
|
|
||||||
|
- `InvalidSite` - valid options: `zillow`, `redfin`, `realtor.com`
|
||||||
|
- `InvalidListingType` - valid options: `for_sale`, `for_rent`, `sold`
|
||||||
|
- `NoResultsFound` - no properties found from your input
|
||||||
|
- `GeoCoordsNotFound` - if Zillow scraper is not able to create geo-coordinates from the location you input
|
||||||
|
|
||||||
|
## Frequently Asked Questions
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Q: Encountering issues with your queries?**
|
||||||
|
**A:** Try a single site and/or broaden the location. If problems persist, [submit an issue](https://github.com/ZacharyHampton/HomeHarvest/issues).
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Q: Received a Forbidden 403 response code?**
|
||||||
|
**A:** This indicates that you have been blocked by the real estate site for sending too many requests. Currently, **Zillow** is particularly aggressive with blocking. We recommend:
|
||||||
|
|
||||||
|
- Waiting a few seconds between requests.
|
||||||
|
- Trying a VPN to change your IP address.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
|||||||
@@ -1,10 +1,14 @@
|
|||||||
|
import pandas as pd
|
||||||
|
from typing import Union
|
||||||
|
import concurrent.futures
|
||||||
|
from concurrent.futures import ThreadPoolExecutor
|
||||||
|
|
||||||
|
from .core.scrapers import ScraperInput
|
||||||
from .core.scrapers.redfin import RedfinScraper
|
from .core.scrapers.redfin import RedfinScraper
|
||||||
from .core.scrapers.realtor import RealtorScraper
|
from .core.scrapers.realtor import RealtorScraper
|
||||||
from .core.scrapers.zillow import ZillowScraper
|
from .core.scrapers.zillow import ZillowScraper
|
||||||
from .core.scrapers.models import ListingType, Property, Building
|
from .core.scrapers.models import ListingType, Property, SiteName
|
||||||
from .core.scrapers import ScraperInput
|
|
||||||
from .exceptions import InvalidSite, InvalidListingType
|
from .exceptions import InvalidSite, InvalidListingType
|
||||||
from typing import Union
|
|
||||||
|
|
||||||
|
|
||||||
_scrapers = {
|
_scrapers = {
|
||||||
@@ -14,11 +18,7 @@ _scrapers = {
|
|||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
def scrape_property(
|
def validate_input(site_name: str, listing_type: str) -> None:
|
||||||
location: str,
|
|
||||||
site_name: str,
|
|
||||||
listing_type: str = "for_sale", #: for_sale, for_rent, sold
|
|
||||||
) -> Union[list[Building], list[Property]]: #: eventually, return pandas dataframe
|
|
||||||
if site_name.lower() not in _scrapers:
|
if site_name.lower() not in _scrapers:
|
||||||
raise InvalidSite(f"Provided site, '{site_name}', does not exist.")
|
raise InvalidSite(f"Provided site, '{site_name}', does not exist.")
|
||||||
|
|
||||||
@@ -27,11 +27,160 @@ def scrape_property(
|
|||||||
f"Provided listing type, '{listing_type}', does not exist."
|
f"Provided listing type, '{listing_type}', does not exist."
|
||||||
)
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def get_ordered_properties(result: Property) -> list[str]:
|
||||||
|
return [
|
||||||
|
"property_url",
|
||||||
|
"site_name",
|
||||||
|
"listing_type",
|
||||||
|
"property_type",
|
||||||
|
"status_text",
|
||||||
|
"currency",
|
||||||
|
"price",
|
||||||
|
"apt_min_price",
|
||||||
|
"apt_max_price",
|
||||||
|
"apt_min_sqft",
|
||||||
|
"apt_max_sqft",
|
||||||
|
"apt_min_beds",
|
||||||
|
"apt_max_beds",
|
||||||
|
"apt_min_baths",
|
||||||
|
"apt_max_baths",
|
||||||
|
"tax_assessed_value",
|
||||||
|
"square_feet",
|
||||||
|
"price_per_sqft",
|
||||||
|
"beds",
|
||||||
|
"baths",
|
||||||
|
"lot_area_value",
|
||||||
|
"lot_area_unit",
|
||||||
|
"street_address",
|
||||||
|
"unit",
|
||||||
|
"city",
|
||||||
|
"state",
|
||||||
|
"zip_code",
|
||||||
|
"country",
|
||||||
|
"posted_time",
|
||||||
|
"bldg_min_beds",
|
||||||
|
"bldg_min_baths",
|
||||||
|
"bldg_min_area",
|
||||||
|
"bldg_unit_count",
|
||||||
|
"bldg_name",
|
||||||
|
"stories",
|
||||||
|
"year_built",
|
||||||
|
"agent_name",
|
||||||
|
"mls_id",
|
||||||
|
"img_src",
|
||||||
|
"latitude",
|
||||||
|
"longitude",
|
||||||
|
"description",
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def process_result(result: Property) -> pd.DataFrame:
|
||||||
|
prop_data = result.__dict__
|
||||||
|
|
||||||
|
prop_data["site_name"] = prop_data["site_name"].value
|
||||||
|
prop_data["listing_type"] = prop_data["listing_type"].value.lower()
|
||||||
|
if "property_type" in prop_data and prop_data["property_type"] is not None:
|
||||||
|
prop_data["property_type"] = prop_data["property_type"].value.lower()
|
||||||
|
else:
|
||||||
|
prop_data["property_type"] = None
|
||||||
|
if "address" in prop_data:
|
||||||
|
address_data = prop_data["address"]
|
||||||
|
prop_data["street_address"] = address_data.street_address
|
||||||
|
prop_data["unit"] = address_data.unit
|
||||||
|
prop_data["city"] = address_data.city
|
||||||
|
prop_data["state"] = address_data.state
|
||||||
|
prop_data["zip_code"] = address_data.zip_code
|
||||||
|
prop_data["country"] = address_data.country
|
||||||
|
|
||||||
|
del prop_data["address"]
|
||||||
|
|
||||||
|
properties_df = pd.DataFrame([prop_data])
|
||||||
|
properties_df = properties_df[get_ordered_properties(result)]
|
||||||
|
|
||||||
|
return properties_df
|
||||||
|
|
||||||
|
|
||||||
|
def _scrape_single_site(
|
||||||
|
location: str, site_name: str, listing_type: str
|
||||||
|
) -> pd.DataFrame:
|
||||||
|
"""
|
||||||
|
Helper function to scrape a single site.
|
||||||
|
"""
|
||||||
|
validate_input(site_name, listing_type)
|
||||||
|
|
||||||
scraper_input = ScraperInput(
|
scraper_input = ScraperInput(
|
||||||
location=location,
|
location=location,
|
||||||
listing_type=ListingType[listing_type.upper()],
|
listing_type=ListingType[listing_type.upper()],
|
||||||
|
site_name=SiteName.get_by_value(site_name.lower()),
|
||||||
)
|
)
|
||||||
|
|
||||||
site = _scrapers[site_name.lower()](scraper_input)
|
site = _scrapers[site_name.lower()](scraper_input)
|
||||||
|
results = site.search()
|
||||||
|
|
||||||
return site.search()
|
properties_dfs = [process_result(result) for result in results]
|
||||||
|
properties_dfs = [
|
||||||
|
df.dropna(axis=1, how="all") for df in properties_dfs if not df.empty
|
||||||
|
]
|
||||||
|
if not properties_dfs:
|
||||||
|
return pd.DataFrame()
|
||||||
|
|
||||||
|
return pd.concat(properties_dfs, ignore_index=True)
|
||||||
|
|
||||||
|
|
||||||
|
def scrape_property(
|
||||||
|
location: str,
|
||||||
|
site_name: Union[str, list[str]] = None,
|
||||||
|
listing_type: str = "for_sale",
|
||||||
|
) -> pd.DataFrame:
|
||||||
|
"""
|
||||||
|
Scrape property from various sites from a given location and listing type.
|
||||||
|
|
||||||
|
:returns: pd.DataFrame
|
||||||
|
:param location: US Location (e.g. 'San Francisco, CA', 'Cook County, IL', '85281', '2530 Al Lipscomb Way')
|
||||||
|
:param site_name: Site name or list of site names (e.g. ['realtor.com', 'zillow'], 'redfin')
|
||||||
|
:param listing_type: Listing type (e.g. 'for_sale', 'for_rent', 'sold')
|
||||||
|
:return: pd.DataFrame containing properties
|
||||||
|
"""
|
||||||
|
if site_name is None:
|
||||||
|
site_name = list(_scrapers.keys())
|
||||||
|
|
||||||
|
if not isinstance(site_name, list):
|
||||||
|
site_name = [site_name]
|
||||||
|
|
||||||
|
results = []
|
||||||
|
|
||||||
|
if len(site_name) == 1:
|
||||||
|
final_df = _scrape_single_site(location, site_name[0], listing_type)
|
||||||
|
results.append(final_df)
|
||||||
|
else:
|
||||||
|
with ThreadPoolExecutor() as executor:
|
||||||
|
futures = {
|
||||||
|
executor.submit(
|
||||||
|
_scrape_single_site, location, s_name, listing_type
|
||||||
|
): s_name
|
||||||
|
for s_name in site_name
|
||||||
|
}
|
||||||
|
|
||||||
|
for future in concurrent.futures.as_completed(futures):
|
||||||
|
result = future.result()
|
||||||
|
results.append(result)
|
||||||
|
|
||||||
|
results = [df for df in results if not df.empty and not df.isna().all().all()]
|
||||||
|
|
||||||
|
if not results:
|
||||||
|
return pd.DataFrame()
|
||||||
|
|
||||||
|
final_df = pd.concat(results, ignore_index=True)
|
||||||
|
|
||||||
|
columns_to_track = ["street_address", "city", "unit"]
|
||||||
|
|
||||||
|
#: validate they exist, otherwise create them
|
||||||
|
for col in columns_to_track:
|
||||||
|
if col not in final_df.columns:
|
||||||
|
final_df[col] = None
|
||||||
|
|
||||||
|
final_df = final_df.drop_duplicates(
|
||||||
|
subset=["street_address", "city", "unit"], keep="first"
|
||||||
|
)
|
||||||
|
return final_df
|
||||||
|
|||||||
57
homeharvest/cli.py
Normal file
57
homeharvest/cli.py
Normal file
@@ -0,0 +1,57 @@
|
|||||||
|
import argparse
|
||||||
|
import datetime
|
||||||
|
from homeharvest import scrape_property
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description="Home Harvest Property Scraper")
|
||||||
|
parser.add_argument(
|
||||||
|
"location", type=str, help="Location to scrape (e.g., San Francisco, CA)"
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--site_name",
|
||||||
|
type=str,
|
||||||
|
nargs="*",
|
||||||
|
default=None,
|
||||||
|
help="Site name(s) to scrape from (e.g., realtor.com zillow)",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--listing_type",
|
||||||
|
type=str,
|
||||||
|
default="for_sale",
|
||||||
|
choices=["for_sale", "for_rent", "sold"],
|
||||||
|
help="Listing type to scrape",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--output",
|
||||||
|
type=str,
|
||||||
|
default="excel",
|
||||||
|
choices=["excel", "csv"],
|
||||||
|
help="Output format",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--filename",
|
||||||
|
type=str,
|
||||||
|
default=None,
|
||||||
|
help="Name of the output file (without extension)",
|
||||||
|
)
|
||||||
|
|
||||||
|
args = parser.parse_args()
|
||||||
|
result = scrape_property(args.location, args.site_name, args.listing_type)
|
||||||
|
|
||||||
|
if not args.filename:
|
||||||
|
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||||
|
args.filename = f"HomeHarvest_{timestamp}"
|
||||||
|
|
||||||
|
if args.output == "excel":
|
||||||
|
output_filename = f"{args.filename}.xlsx"
|
||||||
|
result.to_excel(output_filename, index=False)
|
||||||
|
print(f"Excel file saved as {output_filename}")
|
||||||
|
elif args.output == "csv":
|
||||||
|
output_filename = f"{args.filename}.csv"
|
||||||
|
result.to_csv(output_filename, index=False)
|
||||||
|
print(f"CSV file saved as {output_filename}")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
main()
|
||||||
@@ -1,22 +1,24 @@
|
|||||||
from dataclasses import dataclass
|
from dataclasses import dataclass
|
||||||
import requests
|
import requests
|
||||||
from .models import Property, ListingType
|
from .models import Property, ListingType, SiteName
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class ScraperInput:
|
class ScraperInput:
|
||||||
location: str
|
location: str
|
||||||
listing_type: ListingType
|
listing_type: ListingType
|
||||||
|
site_name: SiteName
|
||||||
proxy_url: str | None = None
|
proxy_url: str | None = None
|
||||||
|
|
||||||
|
|
||||||
class Scraper:
|
class Scraper:
|
||||||
listing_type = ListingType.FOR_SALE
|
|
||||||
|
|
||||||
def __init__(self, scraper_input: ScraperInput):
|
def __init__(self, scraper_input: ScraperInput):
|
||||||
self.location = scraper_input.location
|
self.location = scraper_input.location
|
||||||
|
self.listing_type = scraper_input.listing_type
|
||||||
|
|
||||||
self.session = requests.Session()
|
self.session = requests.Session()
|
||||||
Scraper.listing_type = scraper_input.listing_type
|
self.listing_type = scraper_input.listing_type
|
||||||
|
self.site_name = scraper_input.site_name
|
||||||
|
|
||||||
if scraper_input.proxy_url:
|
if scraper_input.proxy_url:
|
||||||
self.session.proxies = {
|
self.session.proxies = {
|
||||||
|
|||||||
@@ -2,51 +2,111 @@ from dataclasses import dataclass
|
|||||||
from enum import Enum
|
from enum import Enum
|
||||||
|
|
||||||
|
|
||||||
|
class SiteName(Enum):
|
||||||
|
ZILLOW = "zillow"
|
||||||
|
REDFIN = "redfin"
|
||||||
|
REALTOR = "realtor.com"
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_by_value(cls, value):
|
||||||
|
for item in cls:
|
||||||
|
if item.value == value:
|
||||||
|
return item
|
||||||
|
raise ValueError(f"{value} not found in {cls}")
|
||||||
|
|
||||||
|
|
||||||
class ListingType(Enum):
|
class ListingType(Enum):
|
||||||
FOR_SALE = "for_sale"
|
FOR_SALE = "FOR_SALE"
|
||||||
FOR_RENT = "for_rent"
|
FOR_RENT = "FOR_RENT"
|
||||||
SOLD = "sold"
|
SOLD = "SOLD"
|
||||||
|
|
||||||
|
|
||||||
|
class PropertyType(Enum):
|
||||||
|
HOUSE = "HOUSE"
|
||||||
|
BUILDING = "BUILDING"
|
||||||
|
CONDO = "CONDO"
|
||||||
|
TOWNHOUSE = "TOWNHOUSE"
|
||||||
|
SINGLE_FAMILY = "SINGLE_FAMILY"
|
||||||
|
MULTI_FAMILY = "MULTI_FAMILY"
|
||||||
|
MANUFACTURED = "MANUFACTURED"
|
||||||
|
NEW_CONSTRUCTION = "NEW_CONSTRUCTION"
|
||||||
|
APARTMENT = "APARTMENT"
|
||||||
|
APARTMENTS = "APARTMENTS"
|
||||||
|
LAND = "LAND"
|
||||||
|
LOT = "LOT"
|
||||||
|
OTHER = "OTHER"
|
||||||
|
|
||||||
|
BLANK = "BLANK"
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_int_code(cls, code):
|
||||||
|
mapping = {
|
||||||
|
1: cls.HOUSE,
|
||||||
|
2: cls.CONDO,
|
||||||
|
3: cls.TOWNHOUSE,
|
||||||
|
4: cls.MULTI_FAMILY,
|
||||||
|
5: cls.LAND,
|
||||||
|
6: cls.OTHER,
|
||||||
|
8: cls.SINGLE_FAMILY,
|
||||||
|
13: cls.SINGLE_FAMILY,
|
||||||
|
}
|
||||||
|
|
||||||
|
return mapping.get(code, cls.BLANK)
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class Address:
|
class Address:
|
||||||
address_one: str
|
street_address: str
|
||||||
city: str
|
city: str
|
||||||
state: str
|
state: str
|
||||||
zip_code: str
|
zip_code: str
|
||||||
|
unit: str | None = None
|
||||||
address_two: str | None = None
|
country: str | None = None
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class Property:
|
class Property:
|
||||||
|
property_url: str
|
||||||
|
site_name: SiteName
|
||||||
|
listing_type: ListingType
|
||||||
address: Address
|
address: Address
|
||||||
url: str
|
property_type: PropertyType | None = None
|
||||||
|
|
||||||
|
# house for sale
|
||||||
|
price: int | None = None
|
||||||
|
tax_assessed_value: int | None = None
|
||||||
|
currency: str | None = None
|
||||||
|
square_feet: int | None = None
|
||||||
beds: int | None = None
|
beds: int | None = None
|
||||||
baths: float | None = None
|
baths: float | None = None
|
||||||
|
lot_area_value: float | None = None
|
||||||
|
lot_area_unit: str | None = None
|
||||||
stories: int | None = None
|
stories: int | None = None
|
||||||
agent_name: str | None = None
|
|
||||||
year_built: int | None = None
|
year_built: int | None = None
|
||||||
square_feet: int | None = None
|
price_per_sqft: int | None = None
|
||||||
price_per_square_foot: int | None = None
|
|
||||||
year_built: int | None = None
|
|
||||||
price: int | None = None
|
|
||||||
mls_id: str | None = None
|
mls_id: str | None = None
|
||||||
|
|
||||||
listing_type: ListingType | None = None
|
agent_name: str | None = None
|
||||||
lot_size: int | None = None
|
img_src: str | None = None
|
||||||
description: str | None = None
|
description: str | None = None
|
||||||
|
status_text: str | None = None
|
||||||
|
latitude: float | None = None
|
||||||
|
longitude: float | None = None
|
||||||
|
posted_time: str | None = None
|
||||||
|
|
||||||
|
# building for sale
|
||||||
|
bldg_name: str | None = None
|
||||||
|
bldg_unit_count: int | None = None
|
||||||
|
bldg_min_beds: int | None = None
|
||||||
|
bldg_min_baths: float | None = None
|
||||||
|
bldg_min_area: int | None = None
|
||||||
|
|
||||||
@dataclass
|
# apt
|
||||||
class Building:
|
apt_min_beds: int | None = None
|
||||||
address: Address
|
apt_max_beds: int | None = None
|
||||||
url: str
|
apt_min_baths: float | None = None
|
||||||
|
apt_max_baths: float | None = None
|
||||||
num_units: int | None = None
|
apt_min_price: int | None = None
|
||||||
min_unit_price: int | None = None
|
apt_max_price: int | None = None
|
||||||
max_unit_price: int | None = None
|
apt_min_sqft: int | None = None
|
||||||
avg_unit_price: int | None = None
|
apt_max_sqft: int | None = None
|
||||||
|
|
||||||
listing_type: str | None = None
|
|
||||||
|
|||||||
@@ -1,12 +1,16 @@
|
|||||||
import json
|
import json
|
||||||
from ..models import Property, Address
|
from ..models import Property, Address
|
||||||
from .. import Scraper
|
from .. import Scraper
|
||||||
from typing import Any
|
from typing import Any, Generator
|
||||||
|
from ....exceptions import NoResultsFound
|
||||||
|
from ....utils import parse_address_two, parse_unit
|
||||||
|
from concurrent.futures import ThreadPoolExecutor, as_completed
|
||||||
|
|
||||||
|
|
||||||
class RealtorScraper(Scraper):
|
class RealtorScraper(Scraper):
|
||||||
def __init__(self, scraper_input):
|
def __init__(self, scraper_input):
|
||||||
super().__init__(scraper_input)
|
super().__init__(scraper_input)
|
||||||
|
self.search_url = "https://www.realtor.com/api/v1/rdc_search_srp?client_id=rdc-search-new-communities&schema=vesta"
|
||||||
|
|
||||||
def handle_location(self):
|
def handle_location(self):
|
||||||
headers = {
|
headers = {
|
||||||
@@ -26,7 +30,7 @@ class RealtorScraper(Scraper):
|
|||||||
|
|
||||||
params = {
|
params = {
|
||||||
"input": self.location,
|
"input": self.location,
|
||||||
"client_id": "for-sale",
|
"client_id": self.listing_type.value.lower().replace("_", "-"),
|
||||||
"limit": "1",
|
"limit": "1",
|
||||||
"area_types": "city,state,county,postal_code,address,street,neighborhood,school,school_district,university,park",
|
"area_types": "city,state,county,postal_code,address,street,neighborhood,school,school_district,university,park",
|
||||||
}
|
}
|
||||||
@@ -38,14 +42,277 @@ class RealtorScraper(Scraper):
|
|||||||
)
|
)
|
||||||
response_json = response.json()
|
response_json = response.json()
|
||||||
|
|
||||||
return response_json["autocomplete"][0]
|
result = response_json["autocomplete"]
|
||||||
|
|
||||||
|
if not result:
|
||||||
|
raise NoResultsFound("No results found for location: " + self.location)
|
||||||
|
|
||||||
|
return result[0]
|
||||||
|
|
||||||
|
def handle_address(self, property_id: str) -> list[Property]:
|
||||||
|
query = """query Property($property_id: ID!) {
|
||||||
|
property(id: $property_id) {
|
||||||
|
property_id
|
||||||
|
details {
|
||||||
|
date_updated
|
||||||
|
garage
|
||||||
|
permalink
|
||||||
|
year_built
|
||||||
|
stories
|
||||||
|
}
|
||||||
|
address {
|
||||||
|
address_validation_code
|
||||||
|
city
|
||||||
|
country
|
||||||
|
county
|
||||||
|
line
|
||||||
|
postal_code
|
||||||
|
state_code
|
||||||
|
street_direction
|
||||||
|
street_name
|
||||||
|
street_number
|
||||||
|
street_suffix
|
||||||
|
street_post_direction
|
||||||
|
unit_value
|
||||||
|
unit
|
||||||
|
unit_descriptor
|
||||||
|
zip
|
||||||
|
}
|
||||||
|
basic {
|
||||||
|
baths
|
||||||
|
beds
|
||||||
|
price
|
||||||
|
sqft
|
||||||
|
lot_sqft
|
||||||
|
type
|
||||||
|
sold_price
|
||||||
|
}
|
||||||
|
public_record {
|
||||||
|
lot_size
|
||||||
|
sqft
|
||||||
|
stories
|
||||||
|
units
|
||||||
|
year_built
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}"""
|
||||||
|
|
||||||
|
variables = {"property_id": property_id}
|
||||||
|
|
||||||
|
payload = {
|
||||||
|
"query": query,
|
||||||
|
"variables": variables,
|
||||||
|
}
|
||||||
|
|
||||||
|
response = self.session.post(self.search_url, json=payload)
|
||||||
|
response_json = response.json()
|
||||||
|
|
||||||
|
property_info = response_json["data"]["property"]
|
||||||
|
street_address, unit = parse_address_two(property_info["address"]["line"])
|
||||||
|
|
||||||
|
return [
|
||||||
|
Property(
|
||||||
|
site_name=self.site_name,
|
||||||
|
address=Address(
|
||||||
|
street_address=street_address,
|
||||||
|
city=property_info["address"]["city"],
|
||||||
|
state=property_info["address"]["state_code"],
|
||||||
|
zip_code=property_info["address"]["postal_code"],
|
||||||
|
unit=unit,
|
||||||
|
country="USA",
|
||||||
|
),
|
||||||
|
property_url="https://www.realtor.com/realestateandhomes-detail/"
|
||||||
|
+ property_info["details"]["permalink"],
|
||||||
|
beds=property_info["basic"]["beds"],
|
||||||
|
baths=property_info["basic"]["baths"],
|
||||||
|
stories=property_info["details"]["stories"],
|
||||||
|
year_built=property_info["details"]["year_built"],
|
||||||
|
square_feet=property_info["basic"]["sqft"],
|
||||||
|
price_per_sqft=property_info["basic"]["price"]
|
||||||
|
// property_info["basic"]["sqft"]
|
||||||
|
if property_info["basic"]["sqft"] is not None
|
||||||
|
and property_info["basic"]["price"] is not None
|
||||||
|
else None,
|
||||||
|
price=property_info["basic"]["price"],
|
||||||
|
mls_id=property_id,
|
||||||
|
listing_type=self.listing_type,
|
||||||
|
lot_area_value=property_info["public_record"]["lot_size"]
|
||||||
|
if property_info["public_record"] is not None
|
||||||
|
else None,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
def handle_area(
|
||||||
|
self, variables: dict, return_total: bool = False
|
||||||
|
) -> list[Property] | int:
|
||||||
|
query = (
|
||||||
|
"""query Home_search(
|
||||||
|
$city: String,
|
||||||
|
$county: [String],
|
||||||
|
$state_code: String,
|
||||||
|
$postal_code: String
|
||||||
|
$offset: Int,
|
||||||
|
) {
|
||||||
|
home_search(
|
||||||
|
query: {
|
||||||
|
city: $city
|
||||||
|
county: $county
|
||||||
|
postal_code: $postal_code
|
||||||
|
state_code: $state_code
|
||||||
|
status: %s
|
||||||
|
}
|
||||||
|
limit: 200
|
||||||
|
offset: $offset
|
||||||
|
) {
|
||||||
|
count
|
||||||
|
total
|
||||||
|
results {
|
||||||
|
property_id
|
||||||
|
description {
|
||||||
|
baths
|
||||||
|
beds
|
||||||
|
lot_sqft
|
||||||
|
sqft
|
||||||
|
text
|
||||||
|
sold_price
|
||||||
|
stories
|
||||||
|
year_built
|
||||||
|
garage
|
||||||
|
unit_number
|
||||||
|
floor_number
|
||||||
|
}
|
||||||
|
location {
|
||||||
|
address {
|
||||||
|
city
|
||||||
|
country
|
||||||
|
line
|
||||||
|
postal_code
|
||||||
|
state_code
|
||||||
|
state
|
||||||
|
street_direction
|
||||||
|
street_name
|
||||||
|
street_number
|
||||||
|
street_post_direction
|
||||||
|
street_suffix
|
||||||
|
unit
|
||||||
|
coordinate {
|
||||||
|
lon
|
||||||
|
lat
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
list_price
|
||||||
|
price_per_sqft
|
||||||
|
source {
|
||||||
|
id
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}"""
|
||||||
|
% self.listing_type.value.lower()
|
||||||
|
)
|
||||||
|
|
||||||
|
payload = {
|
||||||
|
"query": query,
|
||||||
|
"variables": variables,
|
||||||
|
}
|
||||||
|
|
||||||
|
response = self.session.post(self.search_url, json=payload)
|
||||||
|
response.raise_for_status()
|
||||||
|
response_json = response.json()
|
||||||
|
|
||||||
|
if return_total:
|
||||||
|
return response_json["data"]["home_search"]["total"]
|
||||||
|
|
||||||
|
properties: list[Property] = []
|
||||||
|
|
||||||
|
if (
|
||||||
|
response_json is None
|
||||||
|
or "data" not in response_json
|
||||||
|
or response_json["data"] is None
|
||||||
|
or "home_search" not in response_json["data"]
|
||||||
|
or response_json["data"]["home_search"] is None
|
||||||
|
or "results" not in response_json["data"]["home_search"]
|
||||||
|
):
|
||||||
|
return []
|
||||||
|
|
||||||
|
for result in response_json["data"]["home_search"]["results"]:
|
||||||
|
street_address, unit = parse_address_two(
|
||||||
|
result["location"]["address"]["line"]
|
||||||
|
)
|
||||||
|
realty_property = Property(
|
||||||
|
address=Address(
|
||||||
|
street_address=street_address,
|
||||||
|
city=result["location"]["address"]["city"],
|
||||||
|
state=result["location"]["address"]["state_code"],
|
||||||
|
zip_code=result["location"]["address"]["postal_code"],
|
||||||
|
unit=parse_unit(result["location"]["address"]["unit"]),
|
||||||
|
country="USA",
|
||||||
|
),
|
||||||
|
latitude=result["location"]["address"]["coordinate"]["lat"]
|
||||||
|
if result
|
||||||
|
and result.get("location")
|
||||||
|
and result["location"].get("address")
|
||||||
|
and result["location"]["address"].get("coordinate")
|
||||||
|
and "lat" in result["location"]["address"]["coordinate"]
|
||||||
|
else None,
|
||||||
|
longitude=result["location"]["address"]["coordinate"]["lon"]
|
||||||
|
if result
|
||||||
|
and result.get("location")
|
||||||
|
and result["location"].get("address")
|
||||||
|
and result["location"]["address"].get("coordinate")
|
||||||
|
and "lon" in result["location"]["address"]["coordinate"]
|
||||||
|
else None,
|
||||||
|
site_name=self.site_name,
|
||||||
|
property_url="https://www.realtor.com/realestateandhomes-detail/"
|
||||||
|
+ result["property_id"],
|
||||||
|
beds=result["description"]["beds"],
|
||||||
|
baths=result["description"]["baths"],
|
||||||
|
stories=result["description"]["stories"],
|
||||||
|
year_built=result["description"]["year_built"],
|
||||||
|
square_feet=result["description"]["sqft"],
|
||||||
|
price_per_sqft=result["price_per_sqft"],
|
||||||
|
price=result["list_price"],
|
||||||
|
mls_id=result["property_id"],
|
||||||
|
listing_type=self.listing_type,
|
||||||
|
lot_area_value=result["description"]["lot_sqft"],
|
||||||
|
)
|
||||||
|
|
||||||
|
properties.append(realty_property)
|
||||||
|
|
||||||
|
return properties
|
||||||
|
|
||||||
def search(self):
|
def search(self):
|
||||||
location_info = self.handle_location()
|
location_info = self.handle_location()
|
||||||
location_type = location_info["area_type"]
|
location_type = location_info["area_type"]
|
||||||
|
|
||||||
"""
|
if location_type == "address":
|
||||||
property types:
|
property_id = location_info["mpr_id"]
|
||||||
apartment + building + commercial + condo_townhome + condo_townhome_rowhome_coop + condos + coop + duplex_triplex + farm + investment + land + mobile + multi_family + rental + single_family + townhomes
|
return self.handle_address(property_id)
|
||||||
"""
|
|
||||||
print("a")
|
offset = 0
|
||||||
|
search_variables = {
|
||||||
|
"city": location_info.get("city"),
|
||||||
|
"county": location_info.get("county"),
|
||||||
|
"state_code": location_info.get("state_code"),
|
||||||
|
"postal_code": location_info.get("postal_code"),
|
||||||
|
"offset": offset,
|
||||||
|
}
|
||||||
|
|
||||||
|
total = self.handle_area(search_variables, return_total=True)
|
||||||
|
|
||||||
|
homes = []
|
||||||
|
with ThreadPoolExecutor(max_workers=10) as executor:
|
||||||
|
futures = [
|
||||||
|
executor.submit(
|
||||||
|
self.handle_area,
|
||||||
|
variables=search_variables | {"offset": i},
|
||||||
|
return_total=False,
|
||||||
|
)
|
||||||
|
for i in range(0, total, 200)
|
||||||
|
]
|
||||||
|
|
||||||
|
for future in as_completed(futures):
|
||||||
|
homes.extend(future.result())
|
||||||
|
|
||||||
|
return homes
|
||||||
|
|||||||
@@ -1,12 +1,15 @@
|
|||||||
import json
|
import json
|
||||||
from ..models import Property, Address
|
|
||||||
from .. import Scraper
|
|
||||||
from typing import Any
|
from typing import Any
|
||||||
|
from .. import Scraper
|
||||||
|
from ....utils import parse_address_two, parse_unit
|
||||||
|
from ..models import Property, Address, PropertyType, ListingType, SiteName
|
||||||
|
from ....exceptions import NoResultsFound
|
||||||
|
|
||||||
|
|
||||||
class RedfinScraper(Scraper):
|
class RedfinScraper(Scraper):
|
||||||
def __init__(self, scraper_input):
|
def __init__(self, scraper_input):
|
||||||
super().__init__(scraper_input)
|
super().__init__(scraper_input)
|
||||||
|
self.listing_type = scraper_input.listing_type
|
||||||
|
|
||||||
def _handle_location(self):
|
def _handle_location(self):
|
||||||
url = "https://www.redfin.com/stingray/do/location-autocomplete?v=2&al=1&location={}".format(
|
url = "https://www.redfin.com/stingray/do/location-autocomplete?v=2&al=1&location={}".format(
|
||||||
@@ -24,6 +27,11 @@ class RedfinScraper(Scraper):
|
|||||||
elif match_type == "1":
|
elif match_type == "1":
|
||||||
return "address" #: address, needs to be handled differently
|
return "address" #: address, needs to be handled differently
|
||||||
|
|
||||||
|
if "exactMatch" not in response_json["payload"]:
|
||||||
|
raise NoResultsFound(
|
||||||
|
"No results found for location: {}".format(self.location)
|
||||||
|
)
|
||||||
|
|
||||||
if response_json["payload"]["exactMatch"] is not None:
|
if response_json["payload"]["exactMatch"] is not None:
|
||||||
target = response_json["payload"]["exactMatch"]
|
target = response_json["payload"]["exactMatch"]
|
||||||
else:
|
else:
|
||||||
@@ -31,34 +39,53 @@ class RedfinScraper(Scraper):
|
|||||||
|
|
||||||
return target["id"].split("_")[1], get_region_type(target["type"])
|
return target["id"].split("_")[1], get_region_type(target["type"])
|
||||||
|
|
||||||
@staticmethod
|
def _parse_home(self, home: dict, single_search: bool = False) -> Property:
|
||||||
def _parse_home(home: dict, single_search: bool = False) -> Property:
|
|
||||||
def get_value(key: str) -> Any | None:
|
def get_value(key: str) -> Any | None:
|
||||||
if key in home and "value" in home[key]:
|
if key in home and "value" in home[key]:
|
||||||
return home[key]["value"]
|
return home[key]["value"]
|
||||||
|
|
||||||
if not single_search:
|
if not single_search:
|
||||||
|
street_address, unit = parse_address_two(get_value("streetLine"))
|
||||||
|
unit = parse_unit(get_value("streetLine"))
|
||||||
address = Address(
|
address = Address(
|
||||||
address_one=get_value("streetLine"),
|
street_address=street_address,
|
||||||
city=home["city"],
|
city=home["city"],
|
||||||
state=home["state"],
|
state=home["state"],
|
||||||
zip_code=home["zip"],
|
zip_code=home["zip"],
|
||||||
|
unit=unit,
|
||||||
|
country="USA",
|
||||||
)
|
)
|
||||||
else:
|
else:
|
||||||
address_info = home["streetAddress"]
|
address_info = home["streetAddress"]
|
||||||
|
street_address, unit = parse_address_two(address_info["assembledAddress"])
|
||||||
|
|
||||||
address = Address(
|
address = Address(
|
||||||
address_one=address_info["assembledAddress"],
|
street_address=street_address,
|
||||||
city=home["city"],
|
city=home["city"],
|
||||||
state=home["state"],
|
state=home["state"],
|
||||||
zip_code=home["zip"],
|
zip_code=home["zip"],
|
||||||
|
unit=unit,
|
||||||
|
country="USA",
|
||||||
)
|
)
|
||||||
|
|
||||||
url = "https://www.redfin.com{}".format(home["url"])
|
url = "https://www.redfin.com{}".format(home["url"])
|
||||||
|
#: property_type = home["propertyType"] if "propertyType" in home else None
|
||||||
|
lot_size_data = home.get("lotSize")
|
||||||
|
|
||||||
|
if not isinstance(lot_size_data, int):
|
||||||
|
lot_size = (
|
||||||
|
lot_size_data.get("value", None)
|
||||||
|
if isinstance(lot_size_data, dict)
|
||||||
|
else None
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
lot_size = lot_size_data
|
||||||
|
|
||||||
return Property(
|
return Property(
|
||||||
|
site_name=self.site_name,
|
||||||
|
listing_type=self.listing_type,
|
||||||
address=address,
|
address=address,
|
||||||
url=url,
|
property_url=url,
|
||||||
beds=home["beds"] if "beds" in home else None,
|
beds=home["beds"] if "beds" in home else None,
|
||||||
baths=home["baths"] if "baths" in home else None,
|
baths=home["baths"] if "baths" in home else None,
|
||||||
stories=home["stories"] if "stories" in home else None,
|
stories=home["stories"] if "stories" in home else None,
|
||||||
@@ -68,9 +95,107 @@ class RedfinScraper(Scraper):
|
|||||||
if not single_search
|
if not single_search
|
||||||
else home["yearBuilt"],
|
else home["yearBuilt"],
|
||||||
square_feet=get_value("sqFt"),
|
square_feet=get_value("sqFt"),
|
||||||
price_per_square_foot=get_value("pricePerSqFt"),
|
lot_area_value=lot_size,
|
||||||
|
property_type=PropertyType.from_int_code(home.get("propertyType")),
|
||||||
|
price_per_sqft=get_value("pricePerSqFt"),
|
||||||
price=get_value("price"),
|
price=get_value("price"),
|
||||||
mls_id=get_value("mlsId"),
|
mls_id=get_value("mlsId"),
|
||||||
|
latitude=home["latLong"]["latitude"]
|
||||||
|
if "latLong" in home and "latitude" in home["latLong"]
|
||||||
|
else None,
|
||||||
|
longitude=home["latLong"]["longitude"]
|
||||||
|
if "latLong" in home and "longitude" in home["latLong"]
|
||||||
|
else None,
|
||||||
|
)
|
||||||
|
|
||||||
|
def _handle_rentals(self, region_id, region_type):
|
||||||
|
url = f"https://www.redfin.com/stingray/api/v1/search/rentals?al=1&isRentals=true®ion_id={region_id}®ion_type={region_type}&num_homes=100000"
|
||||||
|
|
||||||
|
response = self.session.get(url)
|
||||||
|
response.raise_for_status()
|
||||||
|
homes = response.json()
|
||||||
|
|
||||||
|
properties_list = []
|
||||||
|
|
||||||
|
for home in homes["homes"]:
|
||||||
|
home_data = home["homeData"]
|
||||||
|
rental_data = home["rentalExtension"]
|
||||||
|
|
||||||
|
property_url = f"https://www.redfin.com{home_data.get('url', '')}"
|
||||||
|
address_info = home_data.get("addressInfo", {})
|
||||||
|
centroid = address_info.get("centroid", {}).get("centroid", {})
|
||||||
|
address = Address(
|
||||||
|
street_address=address_info.get("formattedStreetLine", None),
|
||||||
|
city=address_info.get("city", None),
|
||||||
|
state=address_info.get("state", None),
|
||||||
|
zip_code=address_info.get("zip", None),
|
||||||
|
unit=None,
|
||||||
|
country="US" if address_info.get("countryCode", None) == 1 else None,
|
||||||
|
)
|
||||||
|
|
||||||
|
price_range = rental_data.get("rentPriceRange", {"min": None, "max": None})
|
||||||
|
bed_range = rental_data.get("bedRange", {"min": None, "max": None})
|
||||||
|
bath_range = rental_data.get("bathRange", {"min": None, "max": None})
|
||||||
|
sqft_range = rental_data.get("sqftRange", {"min": None, "max": None})
|
||||||
|
|
||||||
|
property_ = Property(
|
||||||
|
property_url=property_url,
|
||||||
|
site_name=SiteName.REDFIN,
|
||||||
|
listing_type=ListingType.FOR_RENT,
|
||||||
|
address=address,
|
||||||
|
apt_min_beds=bed_range.get("min", None),
|
||||||
|
apt_min_baths=bath_range.get("min", None),
|
||||||
|
apt_max_beds=bed_range.get("max", None),
|
||||||
|
apt_max_baths=bath_range.get("max", None),
|
||||||
|
description=rental_data.get("description", None),
|
||||||
|
latitude=centroid.get("latitude", None),
|
||||||
|
longitude=centroid.get("longitude", None),
|
||||||
|
apt_min_price=price_range.get("min", None),
|
||||||
|
apt_max_price=price_range.get("max", None),
|
||||||
|
apt_min_sqft=sqft_range.get("min", None),
|
||||||
|
apt_max_sqft=sqft_range.get("max", None),
|
||||||
|
img_src=home_data.get("staticMapUrl", None),
|
||||||
|
posted_time=rental_data.get("lastUpdated", None),
|
||||||
|
bldg_name=rental_data.get("propertyName", None),
|
||||||
|
)
|
||||||
|
|
||||||
|
properties_list.append(property_)
|
||||||
|
|
||||||
|
if not properties_list:
|
||||||
|
raise NoResultsFound("No rentals found for the given location.")
|
||||||
|
|
||||||
|
return properties_list
|
||||||
|
|
||||||
|
def _parse_building(self, building: dict) -> Property:
|
||||||
|
street_address = " ".join(
|
||||||
|
[
|
||||||
|
building["address"]["streetNumber"],
|
||||||
|
building["address"]["directionalPrefix"],
|
||||||
|
building["address"]["streetName"],
|
||||||
|
building["address"]["streetType"],
|
||||||
|
]
|
||||||
|
)
|
||||||
|
street_address, unit = parse_address_two(street_address)
|
||||||
|
return Property(
|
||||||
|
site_name=self.site_name,
|
||||||
|
property_type=PropertyType("BUILDING"),
|
||||||
|
address=Address(
|
||||||
|
street_address=street_address,
|
||||||
|
city=building["address"]["city"],
|
||||||
|
state=building["address"]["stateOrProvinceCode"],
|
||||||
|
zip_code=building["address"]["postalCode"],
|
||||||
|
unit=parse_unit(
|
||||||
|
" ".join(
|
||||||
|
[
|
||||||
|
building["address"]["unitType"],
|
||||||
|
building["address"]["unitValue"],
|
||||||
|
]
|
||||||
|
)
|
||||||
|
),
|
||||||
|
),
|
||||||
|
property_url="https://www.redfin.com{}".format(building["url"]),
|
||||||
|
listing_type=self.listing_type,
|
||||||
|
bldg_unit_count=building["numUnitsForSale"],
|
||||||
)
|
)
|
||||||
|
|
||||||
def handle_address(self, home_id: str):
|
def handle_address(self, home_id: str):
|
||||||
@@ -101,14 +226,19 @@ class RedfinScraper(Scraper):
|
|||||||
home_id = region_id
|
home_id = region_id
|
||||||
return self.handle_address(home_id)
|
return self.handle_address(home_id)
|
||||||
|
|
||||||
url = "https://www.redfin.com/stingray/api/gis?al=1®ion_id={}®ion_type={}".format(
|
if self.listing_type == ListingType.FOR_RENT:
|
||||||
region_id, region_type
|
return self._handle_rentals(region_id, region_type)
|
||||||
)
|
else:
|
||||||
|
if self.listing_type == ListingType.FOR_SALE:
|
||||||
response = self.session.get(url)
|
url = f"https://www.redfin.com/stingray/api/gis?al=1®ion_id={region_id}®ion_type={region_type}&num_homes=100000"
|
||||||
response_json = json.loads(response.text.replace("{}&&", ""))
|
else:
|
||||||
|
url = f"https://www.redfin.com/stingray/api/gis?al=1®ion_id={region_id}®ion_type={region_type}&sold_within_days=30&num_homes=100000"
|
||||||
homes = [
|
response = self.session.get(url)
|
||||||
self._parse_home(home) for home in response_json["payload"]["homes"]
|
response_json = json.loads(response.text.replace("{}&&", ""))
|
||||||
] #: support buildings
|
homes = [
|
||||||
return homes
|
self._parse_home(home) for home in response_json["payload"]["homes"]
|
||||||
|
] + [
|
||||||
|
self._parse_building(building)
|
||||||
|
for building in response_json["payload"]["buildings"].values()
|
||||||
|
]
|
||||||
|
return homes
|
||||||
|
|||||||
@@ -1,19 +1,35 @@
|
|||||||
import re
|
import re
|
||||||
import json
|
import json
|
||||||
from ..models import Property, Address, Building, ListingType
|
import string
|
||||||
from ....exceptions import NoResultsFound, PropertyNotFound
|
|
||||||
from .. import Scraper
|
from .. import Scraper
|
||||||
|
from ....utils import parse_address_two, parse_unit
|
||||||
|
from ....exceptions import GeoCoordsNotFound, NoResultsFound
|
||||||
|
from ..models import Property, Address, ListingType, PropertyType
|
||||||
|
|
||||||
|
|
||||||
class ZillowScraper(Scraper):
|
class ZillowScraper(Scraper):
|
||||||
listing_type: ListingType.FOR_SALE
|
|
||||||
|
|
||||||
def __init__(self, scraper_input):
|
def __init__(self, scraper_input):
|
||||||
super().__init__(scraper_input)
|
super().__init__(scraper_input)
|
||||||
|
|
||||||
|
if not self.is_plausible_location(self.location):
|
||||||
|
raise NoResultsFound("Invalid location input: {}".format(self.location))
|
||||||
|
|
||||||
if self.listing_type == ListingType.FOR_SALE:
|
if self.listing_type == ListingType.FOR_SALE:
|
||||||
self.url = f"https://www.zillow.com/homes/for_sale/{self.location}_rb/"
|
self.url = f"https://www.zillow.com/homes/for_sale/{self.location}_rb/"
|
||||||
elif self.listing_type == ListingType.FOR_RENT:
|
elif self.listing_type == ListingType.FOR_RENT:
|
||||||
self.url = f"https://www.zillow.com/homes/for_rent/{self.location}_rb/"
|
self.url = f"https://www.zillow.com/homes/for_rent/{self.location}_rb/"
|
||||||
|
else:
|
||||||
|
self.url = f"https://www.zillow.com/homes/recently_sold/{self.location}_rb/"
|
||||||
|
|
||||||
|
def is_plausible_location(self, location: str) -> bool:
|
||||||
|
url = (
|
||||||
|
"https://www.zillowstatic.com/autocomplete/v3/suggestions?q={"
|
||||||
|
"}&abKey=6666272a-4b99-474c-b857-110ec438732b&clientId=homepage-render"
|
||||||
|
).format(location)
|
||||||
|
|
||||||
|
response = self.session.get(url)
|
||||||
|
|
||||||
|
return response.json()["results"] != []
|
||||||
|
|
||||||
def search(self):
|
def search(self):
|
||||||
resp = self.session.get(self.url, headers=self._get_headers())
|
resp = self.session.get(self.url, headers=self._get_headers())
|
||||||
@@ -34,10 +50,17 @@ class ZillowScraper(Scraper):
|
|||||||
data = json.loads(json_str)
|
data = json.loads(json_str)
|
||||||
|
|
||||||
if "searchPageState" in data["props"]["pageProps"]:
|
if "searchPageState" in data["props"]["pageProps"]:
|
||||||
houses = data["props"]["pageProps"]["searchPageState"]["cat1"][
|
pattern = r'window\.mapBounds = \{\s*"west":\s*(-?\d+\.\d+),\s*"east":\s*(-?\d+\.\d+),\s*"south":\s*(-?\d+\.\d+),\s*"north":\s*(-?\d+\.\d+)\s*\};'
|
||||||
"searchResults"
|
|
||||||
]["listResults"]
|
match = re.search(pattern, content)
|
||||||
return [self._parse_home(house) for house in houses]
|
|
||||||
|
if match:
|
||||||
|
coords = [float(coord) for coord in match.groups()]
|
||||||
|
return self._fetch_properties_backend(coords)
|
||||||
|
|
||||||
|
else:
|
||||||
|
raise GeoCoordsNotFound("Box bounds could not be located.")
|
||||||
|
|
||||||
elif "gdpClientCache" in data["props"]["pageProps"]:
|
elif "gdpClientCache" in data["props"]["pageProps"]:
|
||||||
gdp_client_cache = json.loads(data["props"]["pageProps"]["gdpClientCache"])
|
gdp_client_cache = json.loads(data["props"]["pageProps"]["gdpClientCache"])
|
||||||
main_key = list(gdp_client_cache.keys())[0]
|
main_key = list(gdp_client_cache.keys())[0]
|
||||||
@@ -46,47 +69,166 @@ class ZillowScraper(Scraper):
|
|||||||
property = self._get_single_property_page(property_data)
|
property = self._get_single_property_page(property_data)
|
||||||
|
|
||||||
return [property]
|
return [property]
|
||||||
raise PropertyNotFound("Specific property data not found in the response.")
|
raise NoResultsFound("Specific property data not found in the response.")
|
||||||
|
|
||||||
@classmethod
|
def _fetch_properties_backend(self, coords):
|
||||||
def _parse_home(cls, home: dict):
|
url = "https://www.zillow.com/async-create-search-page-state"
|
||||||
"""
|
|
||||||
This method is used when a user enters a generic location & zillow returns more than one property
|
filter_state_for_sale = {
|
||||||
"""
|
"sortSelection": {
|
||||||
url = (
|
# "value": "globalrelevanceex"
|
||||||
f"https://www.zillow.com{home['detailUrl']}"
|
"value": "days"
|
||||||
if "zillow.com" not in home["detailUrl"]
|
},
|
||||||
else home["detailUrl"]
|
"isAllHomes": {"value": True},
|
||||||
|
}
|
||||||
|
|
||||||
|
filter_state_for_rent = {
|
||||||
|
"isForRent": {"value": True},
|
||||||
|
"isForSaleByAgent": {"value": False},
|
||||||
|
"isForSaleByOwner": {"value": False},
|
||||||
|
"isNewConstruction": {"value": False},
|
||||||
|
"isComingSoon": {"value": False},
|
||||||
|
"isAuction": {"value": False},
|
||||||
|
"isForSaleForeclosure": {"value": False},
|
||||||
|
"isAllHomes": {"value": True},
|
||||||
|
}
|
||||||
|
|
||||||
|
filter_state_sold = {
|
||||||
|
"isRecentlySold": {"value": True},
|
||||||
|
"isForSaleByAgent": {"value": False},
|
||||||
|
"isForSaleByOwner": {"value": False},
|
||||||
|
"isNewConstruction": {"value": False},
|
||||||
|
"isComingSoon": {"value": False},
|
||||||
|
"isAuction": {"value": False},
|
||||||
|
"isForSaleForeclosure": {"value": False},
|
||||||
|
"isAllHomes": {"value": True},
|
||||||
|
}
|
||||||
|
|
||||||
|
selected_filter = (
|
||||||
|
filter_state_for_rent
|
||||||
|
if self.listing_type == ListingType.FOR_RENT
|
||||||
|
else filter_state_for_sale
|
||||||
|
if self.listing_type == ListingType.FOR_SALE
|
||||||
|
else filter_state_sold
|
||||||
)
|
)
|
||||||
|
|
||||||
if "hdpData" in home and "homeInfo" in home["hdpData"]:
|
payload = {
|
||||||
price_data = cls._extract_price(home)
|
"searchQueryState": {
|
||||||
address = cls._extract_address(home)
|
"pagination": {},
|
||||||
agent_name = cls._extract_agent_name(home)
|
"isMapVisible": True,
|
||||||
beds = home["hdpData"]["homeInfo"]["bedrooms"]
|
"mapBounds": {
|
||||||
baths = home["hdpData"]["homeInfo"]["bathrooms"]
|
"west": coords[0],
|
||||||
listing_type = home["hdpData"]["homeInfo"].get("homeType")
|
"east": coords[1],
|
||||||
|
"south": coords[2],
|
||||||
|
"north": coords[3],
|
||||||
|
},
|
||||||
|
"filterState": selected_filter,
|
||||||
|
"isListVisible": True,
|
||||||
|
"mapZoom": 11,
|
||||||
|
},
|
||||||
|
"wants": {"cat1": ["mapResults"]},
|
||||||
|
"isDebugRequest": False,
|
||||||
|
}
|
||||||
|
resp = self.session.put(url, headers=self._get_headers(), json=payload)
|
||||||
|
resp.raise_for_status()
|
||||||
|
a = resp.json()
|
||||||
|
return self._parse_properties(resp.json())
|
||||||
|
|
||||||
return Property(
|
def _parse_properties(self, property_data: dict):
|
||||||
address=address,
|
mapresults = property_data["cat1"]["searchResults"]["mapResults"]
|
||||||
agent_name=agent_name,
|
|
||||||
url=url,
|
|
||||||
beds=beds,
|
|
||||||
baths=baths,
|
|
||||||
listing_type=listing_type,
|
|
||||||
**price_data,
|
|
||||||
)
|
|
||||||
else:
|
|
||||||
keys = ("addressStreet", "addressCity", "addressState", "addressZipcode")
|
|
||||||
address_one, city, state, zip_code = (home[key] for key in keys)
|
|
||||||
address_one, address_two = cls._parse_address_two(address_one)
|
|
||||||
address = Address(address_one, city, state, zip_code, address_two)
|
|
||||||
|
|
||||||
building_info = cls._extract_building_info(home)
|
properties_list = []
|
||||||
return Building(address=address, url=url, **building_info)
|
|
||||||
|
|
||||||
@classmethod
|
for result in mapresults:
|
||||||
def _get_single_property_page(cls, property_data: dict):
|
if "hdpData" in result:
|
||||||
|
home_info = result["hdpData"]["homeInfo"]
|
||||||
|
address_data = {
|
||||||
|
"street_address": parse_address_two(home_info["streetAddress"])[0],
|
||||||
|
"unit": parse_unit(home_info["unit"])
|
||||||
|
if "unit" in home_info
|
||||||
|
else None,
|
||||||
|
"city": home_info["city"],
|
||||||
|
"state": home_info["state"],
|
||||||
|
"zip_code": home_info["zipcode"],
|
||||||
|
"country": home_info["country"],
|
||||||
|
}
|
||||||
|
property_data = {
|
||||||
|
"site_name": self.site_name,
|
||||||
|
"address": Address(**address_data),
|
||||||
|
"property_url": f"https://www.zillow.com{result['detailUrl']}",
|
||||||
|
"beds": int(home_info["bedrooms"])
|
||||||
|
if "bedrooms" in home_info
|
||||||
|
else None,
|
||||||
|
"baths": home_info.get("bathrooms"),
|
||||||
|
"square_feet": int(home_info["livingArea"])
|
||||||
|
if "livingArea" in home_info
|
||||||
|
else None,
|
||||||
|
"currency": home_info["currency"],
|
||||||
|
"price": home_info.get("price"),
|
||||||
|
"tax_assessed_value": int(home_info["taxAssessedValue"])
|
||||||
|
if "taxAssessedValue" in home_info
|
||||||
|
else None,
|
||||||
|
"property_type": PropertyType(home_info["homeType"]),
|
||||||
|
"listing_type": ListingType(
|
||||||
|
home_info["statusType"]
|
||||||
|
if "statusType" in home_info
|
||||||
|
else self.listing_type
|
||||||
|
),
|
||||||
|
"lot_area_value": round(home_info["lotAreaValue"], 2)
|
||||||
|
if "lotAreaValue" in home_info
|
||||||
|
else None,
|
||||||
|
"lot_area_unit": home_info.get("lotAreaUnit"),
|
||||||
|
"latitude": result["latLong"]["latitude"],
|
||||||
|
"longitude": result["latLong"]["longitude"],
|
||||||
|
"status_text": result.get("statusText"),
|
||||||
|
"posted_time": result["variableData"]["text"]
|
||||||
|
if "variableData" in result
|
||||||
|
and "text" in result["variableData"]
|
||||||
|
and result["variableData"]["type"] == "TIME_ON_INFO"
|
||||||
|
else None,
|
||||||
|
"img_src": result.get("imgSrc"),
|
||||||
|
"price_per_sqft": int(home_info["price"] // home_info["livingArea"])
|
||||||
|
if "livingArea" in home_info
|
||||||
|
and home_info["livingArea"] != 0
|
||||||
|
and "price" in home_info
|
||||||
|
else None,
|
||||||
|
}
|
||||||
|
property_obj = Property(**property_data)
|
||||||
|
properties_list.append(property_obj)
|
||||||
|
|
||||||
|
elif "isBuilding" in result:
|
||||||
|
price = result["price"]
|
||||||
|
building_data = {
|
||||||
|
"property_url": f"https://www.zillow.com{result['detailUrl']}",
|
||||||
|
"site_name": self.site_name,
|
||||||
|
"property_type": PropertyType("BUILDING"),
|
||||||
|
"listing_type": ListingType(result["statusType"]),
|
||||||
|
"img_src": result["imgSrc"],
|
||||||
|
"price": int(price.replace("From $", "").replace(",", ""))
|
||||||
|
if "From $" in price
|
||||||
|
else None,
|
||||||
|
"apt_min_price": int(
|
||||||
|
price.replace("$", "").replace(",", "").replace("+/mo", "")
|
||||||
|
)
|
||||||
|
if "+/mo" in price
|
||||||
|
else None,
|
||||||
|
"address": self._extract_address(result["address"]),
|
||||||
|
"bldg_min_beds": result["minBeds"],
|
||||||
|
"currency": "USD",
|
||||||
|
"bldg_min_baths": result["minBaths"],
|
||||||
|
"bldg_min_area": result.get("minArea"),
|
||||||
|
"bldg_unit_count": result["unitCount"],
|
||||||
|
"bldg_name": result.get("communityName"),
|
||||||
|
"status_text": result["statusText"],
|
||||||
|
"latitude": result["latLong"]["latitude"],
|
||||||
|
"longitude": result["latLong"]["longitude"],
|
||||||
|
}
|
||||||
|
building_obj = Property(**building_data)
|
||||||
|
properties_list.append(building_obj)
|
||||||
|
|
||||||
|
return properties_list
|
||||||
|
|
||||||
|
def _get_single_property_page(self, property_data: dict):
|
||||||
"""
|
"""
|
||||||
This method is used when a user enters the exact location & zillow returns just one property
|
This method is used when a user enters the exact location & zillow returns just one property
|
||||||
"""
|
"""
|
||||||
@@ -96,110 +238,93 @@ class ZillowScraper(Scraper):
|
|||||||
else property_data["hdpUrl"]
|
else property_data["hdpUrl"]
|
||||||
)
|
)
|
||||||
address_data = property_data["address"]
|
address_data = property_data["address"]
|
||||||
address_one, address_two = cls._parse_address_two(address_data["streetAddress"])
|
street_address, unit = parse_address_two(address_data["streetAddress"])
|
||||||
address = Address(
|
address = Address(
|
||||||
address_one=address_one,
|
street_address=street_address,
|
||||||
address_two=address_two,
|
unit=unit,
|
||||||
city=address_data["city"],
|
city=address_data["city"],
|
||||||
state=address_data["state"],
|
state=address_data["state"],
|
||||||
zip_code=address_data["zipcode"],
|
zip_code=address_data["zipcode"],
|
||||||
|
country=property_data.get("country"),
|
||||||
)
|
)
|
||||||
|
property_type = property_data.get("homeType", None)
|
||||||
return Property(
|
return Property(
|
||||||
|
site_name=self.site_name,
|
||||||
address=address,
|
address=address,
|
||||||
url=url,
|
property_url=url,
|
||||||
beds=property_data.get("bedrooms", None),
|
beds=property_data.get("bedrooms", None),
|
||||||
baths=property_data.get("bathrooms", None),
|
baths=property_data.get("bathrooms", None),
|
||||||
year_built=property_data.get("yearBuilt", None),
|
year_built=property_data.get("yearBuilt", None),
|
||||||
price=property_data.get("price", None),
|
price=property_data.get("price", None),
|
||||||
lot_size=property_data.get("lotSize", None),
|
tax_assessed_value=property_data.get("taxAssessedValue", None),
|
||||||
|
latitude=property_data.get("latitude"),
|
||||||
|
longitude=property_data.get("longitude"),
|
||||||
|
img_src=property_data.get("streetViewTileImageUrlMediumAddress"),
|
||||||
|
currency=property_data.get("currency", None),
|
||||||
|
lot_area_value=property_data.get("lotAreaValue"),
|
||||||
|
lot_area_unit=property_data["lotAreaUnits"].lower()
|
||||||
|
if "lotAreaUnits" in property_data
|
||||||
|
else None,
|
||||||
agent_name=property_data.get("attributionInfo", {}).get("agentName", None),
|
agent_name=property_data.get("attributionInfo", {}).get("agentName", None),
|
||||||
stories=property_data.get("resoFacts", {}).get("stories", None),
|
stories=property_data.get("resoFacts", {}).get("stories", None),
|
||||||
description=property_data.get("description", None),
|
description=property_data.get("description", None),
|
||||||
mls_id=property_data.get("attributionInfo", {}).get("mlsId", None),
|
mls_id=property_data.get("attributionInfo", {}).get("mlsId", None),
|
||||||
price_per_square_foot=property_data.get("resoFacts", {}).get(
|
price_per_sqft=property_data.get("resoFacts", {}).get(
|
||||||
"pricePerSquareFoot", None
|
"pricePerSquareFoot", None
|
||||||
),
|
),
|
||||||
square_feet=property_data.get("livingArea", None),
|
square_feet=property_data.get("livingArea", None),
|
||||||
listing_type=property_data.get("homeType", None),
|
property_type=PropertyType(property_type),
|
||||||
|
listing_type=self.listing_type,
|
||||||
)
|
)
|
||||||
|
|
||||||
@classmethod
|
def _extract_address(self, address_str):
|
||||||
def _extract_building_info(cls, home: dict) -> dict:
|
"""
|
||||||
num_units = len(home["units"])
|
Extract address components from a string formatted like '555 Wedglea Dr, Dallas, TX',
|
||||||
prices = [
|
and return an Address object.
|
||||||
int(unit["price"].replace("$", "").replace(",", "").split("+")[0])
|
"""
|
||||||
for unit in home["units"]
|
parts = address_str.split(", ")
|
||||||
]
|
|
||||||
return {
|
|
||||||
"listing_type": cls.listing_type,
|
|
||||||
"num_units": len(home["units"]),
|
|
||||||
"min_unit_price": min(
|
|
||||||
(
|
|
||||||
int(unit["price"].replace("$", "").replace(",", "").split("+")[0])
|
|
||||||
for unit in home["units"]
|
|
||||||
)
|
|
||||||
),
|
|
||||||
"max_unit_price": max(
|
|
||||||
(
|
|
||||||
int(unit["price"].replace("$", "").replace(",", "").split("+")[0])
|
|
||||||
for unit in home["units"]
|
|
||||||
)
|
|
||||||
),
|
|
||||||
"avg_unit_price": sum(prices) // len(prices) if num_units else None,
|
|
||||||
}
|
|
||||||
|
|
||||||
@staticmethod
|
if len(parts) != 3:
|
||||||
def _extract_price(home: dict) -> dict:
|
raise ValueError(f"Unexpected address format: {address_str}")
|
||||||
price = int(home["hdpData"]["homeInfo"]["priceForHDP"])
|
|
||||||
square_feet = home["hdpData"]["homeInfo"].get("livingArea")
|
|
||||||
|
|
||||||
lot_size = home["hdpData"]["homeInfo"].get("lotAreaValue")
|
street_address = parts[0].strip()
|
||||||
price_per_square_foot = price // square_feet if square_feet and price else None
|
city = parts[1].strip()
|
||||||
|
state_zip = parts[2].split(" ")
|
||||||
|
|
||||||
return {
|
if len(state_zip) == 1:
|
||||||
k: v
|
state = state_zip[0].strip()
|
||||||
for k, v in locals().items()
|
zip_code = None
|
||||||
if k in ["price", "square_feet", "lot_size", "price_per_square_foot"]
|
elif len(state_zip) == 2:
|
||||||
}
|
state = state_zip[0].strip()
|
||||||
|
zip_code = state_zip[1].strip()
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unexpected state/zip format in address: {address_str}")
|
||||||
|
|
||||||
@staticmethod
|
street_address, unit = parse_address_two(street_address)
|
||||||
def _extract_agent_name(home: dict) -> str | None:
|
return Address(
|
||||||
broker_str = home.get("brokerName", "")
|
street_address=street_address,
|
||||||
match = re.search(r"Listing by: (.+)", broker_str)
|
city=city,
|
||||||
return match.group(1) if match else None
|
unit=unit,
|
||||||
|
state=state,
|
||||||
@staticmethod
|
zip_code=zip_code,
|
||||||
def _parse_address_two(address_one: str):
|
country="USA",
|
||||||
apt_match = re.search(r"(APT\s*.+|#[\s\S]+)$", address_one, re.I)
|
|
||||||
address_two = apt_match.group().strip() if apt_match else None
|
|
||||||
address_one = (
|
|
||||||
address_one.replace(address_two, "").strip() if address_two else address_one
|
|
||||||
)
|
)
|
||||||
return address_one, address_two
|
|
||||||
|
|
||||||
@staticmethod
|
|
||||||
def _extract_address(home: dict) -> Address:
|
|
||||||
keys = ("streetAddress", "city", "state", "zipcode")
|
|
||||||
address_one, city, state, zip_code = (
|
|
||||||
home["hdpData"]["homeInfo"][key] for key in keys
|
|
||||||
)
|
|
||||||
address_one, address_two = ZillowScraper._parse_address_two(address_one)
|
|
||||||
return Address(address_one, city, state, zip_code, address_two=address_two)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _get_headers():
|
def _get_headers():
|
||||||
return {
|
return {
|
||||||
"authority": "parser-external.geo.moveaws.com",
|
"authority": "www.zillow.com",
|
||||||
"accept": "*/*",
|
"accept": "*/*",
|
||||||
"accept-language": "en-US,en;q=0.9",
|
"accept-language": "en-US,en;q=0.9",
|
||||||
|
"content-type": "application/json",
|
||||||
|
"cookie": 'zjs_user_id=null; zg_anonymous_id=%220976ab81-2950-4013-98f0-108b15a554d2%22; zguid=24|%246b1bc625-3955-4d1e-a723-e59602e4ed08; g_state={"i_p":1693611172520,"i_l":1}; zgsession=1|d48820e2-1659-4d2f-b7d2-99a8127dd4f3; zjs_anonymous_id=%226b1bc625-3955-4d1e-a723-e59602e4ed08%22; JSESSIONID=82E8274D3DC8AF3AB9C8E613B38CF861; search=6|1697585860120%7Crb%3DDallas%252C-TX%26rect%3D33.016646%252C-96.555516%252C32.618763%252C-96.999347%26disp%3Dmap%26mdm%3Dauto%26sort%3Ddays%26listPriceActive%3D1%26fs%3D1%26fr%3D0%26mmm%3D0%26rs%3D0%26ah%3D0%26singlestory%3D0%26abo%3D0%26garage%3D0%26pool%3D0%26ac%3D0%26waterfront%3D0%26finished%3D0%26unfinished%3D0%26cityview%3D0%26mountainview%3D0%26parkview%3D0%26waterview%3D0%26hoadata%3D1%263dhome%3D0%26commuteMode%3Ddriving%26commuteTimeOfDay%3Dnow%09%0938128%09%7B%22isList%22%3Atrue%2C%22isMap%22%3Atrue%7D%09%09%09%09%09; AWSALB=gAlFj5Ngnd4bWP8k7CME/+YlTtX9bHK4yEkdPHa3VhL6K523oGyysFxBEpE1HNuuyL+GaRPvt2i/CSseAb+zEPpO4SNjnbLAJzJOOO01ipnWN3ZgPaa5qdv+fAki; AWSALBCORS=gAlFj5Ngnd4bWP8k7CME/+YlTtX9bHK4yEkdPHa3VhL6K523oGyysFxBEpE1HNuuyL+GaRPvt2i/CSseAb+zEPpO4SNjnbLAJzJOOO01ipnWN3ZgPaa5qdv+fAki; search=6|1697587741808%7Crect%3D33.37188814545521%2C-96.34484483007813%2C32.260490641365685%2C-97.21001816992188%26disp%3Dmap%26mdm%3Dauto%26p%3D1%26sort%3Ddays%26z%3D1%26listPriceActive%3D1%26fs%3D1%26fr%3D0%26mmm%3D0%26rs%3D0%26ah%3D0%26singlestory%3D0%26housing-connector%3D0%26abo%3D0%26garage%3D0%26pool%3D0%26ac%3D0%26waterfront%3D0%26finished%3D0%26unfinished%3D0%26cityview%3D0%26mountainview%3D0%26parkview%3D0%26waterview%3D0%26hoadata%3D1%26zillow-owned%3D0%263dhome%3D0%26featuredMultiFamilyBuilding%3D0%26commuteMode%3Ddriving%26commuteTimeOfDay%3Dnow%09%09%09%7B%22isList%22%3Atrue%2C%22isMap%22%3Atrue%7D%09%09%09%09%09',
|
||||||
"origin": "https://www.zillow.com",
|
"origin": "https://www.zillow.com",
|
||||||
"referer": "https://www.zillow.com/",
|
"referer": "https://www.zillow.com",
|
||||||
"sec-ch-ua": '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
|
"sec-ch-ua": '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
|
||||||
"sec-ch-ua-mobile": "?0",
|
"sec-ch-ua-mobile": "?0",
|
||||||
"sec-ch-ua-platform": '"Windows"',
|
"sec-ch-ua-platform": '"Windows"',
|
||||||
"sec-fetch-dest": "empty",
|
"sec-fetch-dest": "empty",
|
||||||
"sec-fetch-mode": "cors",
|
"sec-fetch-mode": "cors",
|
||||||
"sec-fetch-site": "cross-site",
|
"sec-fetch-site": "same-origin",
|
||||||
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
|
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -10,5 +10,5 @@ class NoResultsFound(Exception):
|
|||||||
"""Raised when no results are found for the given location"""
|
"""Raised when no results are found for the given location"""
|
||||||
|
|
||||||
|
|
||||||
class PropertyNotFound(Exception):
|
class GeoCoordsNotFound(Exception):
|
||||||
"""Raised when no property is found for the given address"""
|
"""Raised when no property is found for the given address"""
|
||||||
|
|||||||
48
homeharvest/utils.py
Normal file
48
homeharvest/utils.py
Normal file
@@ -0,0 +1,48 @@
|
|||||||
|
import re
|
||||||
|
|
||||||
|
|
||||||
|
def parse_address_two(street_address: str) -> tuple:
|
||||||
|
if not street_address:
|
||||||
|
return street_address, None
|
||||||
|
|
||||||
|
apt_match = re.search(
|
||||||
|
r"(APT\s*[\dA-Z]+|#[\dA-Z]+|UNIT\s*[\dA-Z]+|LOT\s*[\dA-Z]+|SUITE\s*[\dA-Z]+)$",
|
||||||
|
street_address,
|
||||||
|
re.I,
|
||||||
|
)
|
||||||
|
|
||||||
|
if apt_match:
|
||||||
|
apt_str = apt_match.group().strip()
|
||||||
|
cleaned_apt_str = re.sub(
|
||||||
|
r"(APT\s*|UNIT\s*|LOT\s*|SUITE\s*)", "#", apt_str, flags=re.I
|
||||||
|
)
|
||||||
|
|
||||||
|
main_address = street_address.replace(apt_str, "").strip()
|
||||||
|
return main_address, cleaned_apt_str
|
||||||
|
else:
|
||||||
|
return street_address, None
|
||||||
|
|
||||||
|
|
||||||
|
def parse_unit(street_address: str):
|
||||||
|
if not street_address:
|
||||||
|
return None
|
||||||
|
apt_match = re.search(
|
||||||
|
r"(APT\s*[\dA-Z]+|#[\dA-Z]+|UNIT\s*[\dA-Z]+|LOT\s*[\dA-Z]+)$",
|
||||||
|
street_address,
|
||||||
|
re.I,
|
||||||
|
)
|
||||||
|
|
||||||
|
if apt_match:
|
||||||
|
apt_str = apt_match.group().strip()
|
||||||
|
apt_str = re.sub(r"(APT\s*|UNIT\s*|LOT\s*)", "#", apt_str, flags=re.I)
|
||||||
|
return apt_str
|
||||||
|
else:
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
print(parse_address_two("4303 E Cactus Rd Apt 126"))
|
||||||
|
print(parse_address_two("1234 Elm Street apt 2B"))
|
||||||
|
print(parse_address_two("1234 Elm Street UNIT 3A"))
|
||||||
|
print(parse_address_two("1234 Elm Street unit 3A"))
|
||||||
|
print(parse_address_two("1234 Elm Street SuIte 3A"))
|
||||||
210
poetry.lock
generated
210
poetry.lock
generated
@@ -106,6 +106,17 @@ files = [
|
|||||||
{file = "colorama-0.4.6.tar.gz", hash = "sha256:08695f5cb7ed6e0531a20572697297273c47b8cae5a63ffc6d6ed5c201be6e44"},
|
{file = "colorama-0.4.6.tar.gz", hash = "sha256:08695f5cb7ed6e0531a20572697297273c47b8cae5a63ffc6d6ed5c201be6e44"},
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "et-xmlfile"
|
||||||
|
version = "1.1.0"
|
||||||
|
description = "An implementation of lxml.xmlfile for the standard library"
|
||||||
|
optional = false
|
||||||
|
python-versions = ">=3.6"
|
||||||
|
files = [
|
||||||
|
{file = "et_xmlfile-1.1.0-py3-none-any.whl", hash = "sha256:a2ba85d1d6a74ef63837eed693bcb89c3f752169b0e3e7ae5b16ca5e1b3deada"},
|
||||||
|
{file = "et_xmlfile-1.1.0.tar.gz", hash = "sha256:8eb9e2bc2f8c97e37a2dc85a09ecdcdec9d8a396530a6d5a33b30b9a92da0c5c"},
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "exceptiongroup"
|
name = "exceptiongroup"
|
||||||
version = "1.1.3"
|
version = "1.1.3"
|
||||||
@@ -142,6 +153,95 @@ files = [
|
|||||||
{file = "iniconfig-2.0.0.tar.gz", hash = "sha256:2d91e135bf72d31a410b17c16da610a82cb55f6b0477d1a902134b24a455b8b3"},
|
{file = "iniconfig-2.0.0.tar.gz", hash = "sha256:2d91e135bf72d31a410b17c16da610a82cb55f6b0477d1a902134b24a455b8b3"},
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "numpy"
|
||||||
|
version = "1.25.2"
|
||||||
|
description = "Fundamental package for array computing in Python"
|
||||||
|
optional = false
|
||||||
|
python-versions = ">=3.9"
|
||||||
|
files = [
|
||||||
|
{file = "numpy-1.25.2-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:db3ccc4e37a6873045580d413fe79b68e47a681af8db2e046f1dacfa11f86eb3"},
|
||||||
|
{file = "numpy-1.25.2-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:90319e4f002795ccfc9050110bbbaa16c944b1c37c0baeea43c5fb881693ae1f"},
|
||||||
|
{file = "numpy-1.25.2-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:dfe4a913e29b418d096e696ddd422d8a5d13ffba4ea91f9f60440a3b759b0187"},
|
||||||
|
{file = "numpy-1.25.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:f08f2e037bba04e707eebf4bc934f1972a315c883a9e0ebfa8a7756eabf9e357"},
|
||||||
|
{file = "numpy-1.25.2-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:bec1e7213c7cb00d67093247f8c4db156fd03075f49876957dca4711306d39c9"},
|
||||||
|
{file = "numpy-1.25.2-cp310-cp310-win32.whl", hash = "sha256:7dc869c0c75988e1c693d0e2d5b26034644399dd929bc049db55395b1379e044"},
|
||||||
|
{file = "numpy-1.25.2-cp310-cp310-win_amd64.whl", hash = "sha256:834b386f2b8210dca38c71a6e0f4fd6922f7d3fcff935dbe3a570945acb1b545"},
|
||||||
|
{file = "numpy-1.25.2-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:c5462d19336db4560041517dbb7759c21d181a67cb01b36ca109b2ae37d32418"},
|
||||||
|
{file = "numpy-1.25.2-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:c5652ea24d33585ea39eb6a6a15dac87a1206a692719ff45d53c5282e66d4a8f"},
|
||||||
|
{file = "numpy-1.25.2-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:0d60fbae8e0019865fc4784745814cff1c421df5afee233db6d88ab4f14655a2"},
|
||||||
|
{file = "numpy-1.25.2-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:60e7f0f7f6d0eee8364b9a6304c2845b9c491ac706048c7e8cf47b83123b8dbf"},
|
||||||
|
{file = "numpy-1.25.2-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:bb33d5a1cf360304754913a350edda36d5b8c5331a8237268c48f91253c3a364"},
|
||||||
|
{file = "numpy-1.25.2-cp311-cp311-win32.whl", hash = "sha256:5883c06bb92f2e6c8181df7b39971a5fb436288db58b5a1c3967702d4278691d"},
|
||||||
|
{file = "numpy-1.25.2-cp311-cp311-win_amd64.whl", hash = "sha256:5c97325a0ba6f9d041feb9390924614b60b99209a71a69c876f71052521d42a4"},
|
||||||
|
{file = "numpy-1.25.2-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:b79e513d7aac42ae918db3ad1341a015488530d0bb2a6abcbdd10a3a829ccfd3"},
|
||||||
|
{file = "numpy-1.25.2-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:eb942bfb6f84df5ce05dbf4b46673ffed0d3da59f13635ea9b926af3deb76926"},
|
||||||
|
{file = "numpy-1.25.2-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:3e0746410e73384e70d286f93abf2520035250aad8c5714240b0492a7302fdca"},
|
||||||
|
{file = "numpy-1.25.2-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:d7806500e4f5bdd04095e849265e55de20d8cc4b661b038957354327f6d9b295"},
|
||||||
|
{file = "numpy-1.25.2-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:8b77775f4b7df768967a7c8b3567e309f617dd5e99aeb886fa14dc1a0791141f"},
|
||||||
|
{file = "numpy-1.25.2-cp39-cp39-win32.whl", hash = "sha256:2792d23d62ec51e50ce4d4b7d73de8f67a2fd3ea710dcbc8563a51a03fb07b01"},
|
||||||
|
{file = "numpy-1.25.2-cp39-cp39-win_amd64.whl", hash = "sha256:76b4115d42a7dfc5d485d358728cdd8719be33cc5ec6ec08632a5d6fca2ed380"},
|
||||||
|
{file = "numpy-1.25.2-pp39-pypy39_pp73-macosx_10_9_x86_64.whl", hash = "sha256:1a1329e26f46230bf77b02cc19e900db9b52f398d6722ca853349a782d4cff55"},
|
||||||
|
{file = "numpy-1.25.2-pp39-pypy39_pp73-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:4c3abc71e8b6edba80a01a52e66d83c5d14433cbcd26a40c329ec7ed09f37901"},
|
||||||
|
{file = "numpy-1.25.2-pp39-pypy39_pp73-win_amd64.whl", hash = "sha256:1b9735c27cea5d995496f46a8b1cd7b408b3f34b6d50459d9ac8fe3a20cc17bf"},
|
||||||
|
{file = "numpy-1.25.2.tar.gz", hash = "sha256:fd608e19c8d7c55021dffd43bfe5492fab8cc105cc8986f813f8c3c048b38760"},
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "numpy"
|
||||||
|
version = "1.26.0"
|
||||||
|
description = "Fundamental package for array computing in Python"
|
||||||
|
optional = false
|
||||||
|
python-versions = "<3.13,>=3.9"
|
||||||
|
files = [
|
||||||
|
{file = "numpy-1.26.0-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:f8db2f125746e44dce707dd44d4f4efeea8d7e2b43aace3f8d1f235cfa2733dd"},
|
||||||
|
{file = "numpy-1.26.0-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:0621f7daf973d34d18b4e4bafb210bbaf1ef5e0100b5fa750bd9cde84c7ac292"},
|
||||||
|
{file = "numpy-1.26.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:51be5f8c349fdd1a5568e72713a21f518e7d6707bcf8503b528b88d33b57dc68"},
|
||||||
|
{file = "numpy-1.26.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:767254ad364991ccfc4d81b8152912e53e103ec192d1bb4ea6b1f5a7117040be"},
|
||||||
|
{file = "numpy-1.26.0-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:436c8e9a4bdeeee84e3e59614d38c3dbd3235838a877af8c211cfcac8a80b8d3"},
|
||||||
|
{file = "numpy-1.26.0-cp310-cp310-win32.whl", hash = "sha256:c2e698cb0c6dda9372ea98a0344245ee65bdc1c9dd939cceed6bb91256837896"},
|
||||||
|
{file = "numpy-1.26.0-cp310-cp310-win_amd64.whl", hash = "sha256:09aaee96c2cbdea95de76ecb8a586cb687d281c881f5f17bfc0fb7f5890f6b91"},
|
||||||
|
{file = "numpy-1.26.0-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:637c58b468a69869258b8ae26f4a4c6ff8abffd4a8334c830ffb63e0feefe99a"},
|
||||||
|
{file = "numpy-1.26.0-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:306545e234503a24fe9ae95ebf84d25cba1fdc27db971aa2d9f1ab6bba19a9dd"},
|
||||||
|
{file = "numpy-1.26.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:8c6adc33561bd1d46f81131d5352348350fc23df4d742bb246cdfca606ea1208"},
|
||||||
|
{file = "numpy-1.26.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:e062aa24638bb5018b7841977c360d2f5917268d125c833a686b7cbabbec496c"},
|
||||||
|
{file = "numpy-1.26.0-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:546b7dd7e22f3c6861463bebb000646fa730e55df5ee4a0224408b5694cc6148"},
|
||||||
|
{file = "numpy-1.26.0-cp311-cp311-win32.whl", hash = "sha256:c0b45c8b65b79337dee5134d038346d30e109e9e2e9d43464a2970e5c0e93229"},
|
||||||
|
{file = "numpy-1.26.0-cp311-cp311-win_amd64.whl", hash = "sha256:eae430ecf5794cb7ae7fa3808740b015aa80747e5266153128ef055975a72b99"},
|
||||||
|
{file = "numpy-1.26.0-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:166b36197e9debc4e384e9c652ba60c0bacc216d0fc89e78f973a9760b503388"},
|
||||||
|
{file = "numpy-1.26.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:f042f66d0b4ae6d48e70e28d487376204d3cbf43b84c03bac57e28dac6151581"},
|
||||||
|
{file = "numpy-1.26.0-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:e5e18e5b14a7560d8acf1c596688f4dfd19b4f2945b245a71e5af4ddb7422feb"},
|
||||||
|
{file = "numpy-1.26.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:7f6bad22a791226d0a5c7c27a80a20e11cfe09ad5ef9084d4d3fc4a299cca505"},
|
||||||
|
{file = "numpy-1.26.0-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:4acc65dd65da28060e206c8f27a573455ed724e6179941edb19f97e58161bb69"},
|
||||||
|
{file = "numpy-1.26.0-cp312-cp312-win32.whl", hash = "sha256:bb0d9a1aaf5f1cb7967320e80690a1d7ff69f1d47ebc5a9bea013e3a21faec95"},
|
||||||
|
{file = "numpy-1.26.0-cp312-cp312-win_amd64.whl", hash = "sha256:ee84ca3c58fe48b8ddafdeb1db87388dce2c3c3f701bf447b05e4cfcc3679112"},
|
||||||
|
{file = "numpy-1.26.0-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:4a873a8180479bc829313e8d9798d5234dfacfc2e8a7ac188418189bb8eafbd2"},
|
||||||
|
{file = "numpy-1.26.0-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:914b28d3215e0c721dc75db3ad6d62f51f630cb0c277e6b3bcb39519bed10bd8"},
|
||||||
|
{file = "numpy-1.26.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:c78a22e95182fb2e7874712433eaa610478a3caf86f28c621708d35fa4fd6e7f"},
|
||||||
|
{file = "numpy-1.26.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:86f737708b366c36b76e953c46ba5827d8c27b7a8c9d0f471810728e5a2fe57c"},
|
||||||
|
{file = "numpy-1.26.0-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:b44e6a09afc12952a7d2a58ca0a2429ee0d49a4f89d83a0a11052da696440e49"},
|
||||||
|
{file = "numpy-1.26.0-cp39-cp39-win32.whl", hash = "sha256:5671338034b820c8d58c81ad1dafc0ed5a00771a82fccc71d6438df00302094b"},
|
||||||
|
{file = "numpy-1.26.0-cp39-cp39-win_amd64.whl", hash = "sha256:020cdbee66ed46b671429c7265cf00d8ac91c046901c55684954c3958525dab2"},
|
||||||
|
{file = "numpy-1.26.0-pp39-pypy39_pp73-macosx_10_9_x86_64.whl", hash = "sha256:0792824ce2f7ea0c82ed2e4fecc29bb86bee0567a080dacaf2e0a01fe7654369"},
|
||||||
|
{file = "numpy-1.26.0-pp39-pypy39_pp73-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:7d484292eaeb3e84a51432a94f53578689ffdea3f90e10c8b203a99be5af57d8"},
|
||||||
|
{file = "numpy-1.26.0-pp39-pypy39_pp73-win_amd64.whl", hash = "sha256:186ba67fad3c60dbe8a3abff3b67a91351100f2661c8e2a80364ae6279720299"},
|
||||||
|
{file = "numpy-1.26.0.tar.gz", hash = "sha256:f93fc78fe8bf15afe2b8d6b6499f1c73953169fad1e9a8dd086cdff3190e7fdf"},
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "openpyxl"
|
||||||
|
version = "3.1.2"
|
||||||
|
description = "A Python library to read/write Excel 2010 xlsx/xlsm files"
|
||||||
|
optional = false
|
||||||
|
python-versions = ">=3.6"
|
||||||
|
files = [
|
||||||
|
{file = "openpyxl-3.1.2-py2.py3-none-any.whl", hash = "sha256:f91456ead12ab3c6c2e9491cf33ba6d08357d802192379bb482f1033ade496f5"},
|
||||||
|
{file = "openpyxl-3.1.2.tar.gz", hash = "sha256:a6f5977418eff3b2d5500d54d9db50c8277a368436f4e4f8ddb1be3422870184"},
|
||||||
|
]
|
||||||
|
|
||||||
|
[package.dependencies]
|
||||||
|
et-xmlfile = "*"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "packaging"
|
name = "packaging"
|
||||||
version = "23.1"
|
version = "23.1"
|
||||||
@@ -153,6 +253,67 @@ files = [
|
|||||||
{file = "packaging-23.1.tar.gz", hash = "sha256:a392980d2b6cffa644431898be54b0045151319d1e7ec34f0cfed48767dd334f"},
|
{file = "packaging-23.1.tar.gz", hash = "sha256:a392980d2b6cffa644431898be54b0045151319d1e7ec34f0cfed48767dd334f"},
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "pandas"
|
||||||
|
version = "2.1.0"
|
||||||
|
description = "Powerful data structures for data analysis, time series, and statistics"
|
||||||
|
optional = false
|
||||||
|
python-versions = ">=3.9"
|
||||||
|
files = [
|
||||||
|
{file = "pandas-2.1.0-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:40dd20439ff94f1b2ed55b393ecee9cb6f3b08104c2c40b0cb7186a2f0046242"},
|
||||||
|
{file = "pandas-2.1.0-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:d4f38e4fedeba580285eaac7ede4f686c6701a9e618d8a857b138a126d067f2f"},
|
||||||
|
{file = "pandas-2.1.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:6e6a0fe052cf27ceb29be9429428b4918f3740e37ff185658f40d8702f0b3e09"},
|
||||||
|
{file = "pandas-2.1.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:9d81e1813191070440d4c7a413cb673052b3b4a984ffd86b8dd468c45742d3cc"},
|
||||||
|
{file = "pandas-2.1.0-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:eb20252720b1cc1b7d0b2879ffc7e0542dd568f24d7c4b2347cb035206936421"},
|
||||||
|
{file = "pandas-2.1.0-cp310-cp310-win_amd64.whl", hash = "sha256:38f74ef7ebc0ffb43b3d633e23d74882bce7e27bfa09607f3c5d3e03ffd9a4a5"},
|
||||||
|
{file = "pandas-2.1.0-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:cda72cc8c4761c8f1d97b169661f23a86b16fdb240bdc341173aee17e4d6cedd"},
|
||||||
|
{file = "pandas-2.1.0-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:d97daeac0db8c993420b10da4f5f5b39b01fc9ca689a17844e07c0a35ac96b4b"},
|
||||||
|
{file = "pandas-2.1.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:d8c58b1113892e0c8078f006a167cc210a92bdae23322bb4614f2f0b7a4b510f"},
|
||||||
|
{file = "pandas-2.1.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:629124923bcf798965b054a540f9ccdfd60f71361255c81fa1ecd94a904b9dd3"},
|
||||||
|
{file = "pandas-2.1.0-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:70cf866af3ab346a10debba8ea78077cf3a8cd14bd5e4bed3d41555a3280041c"},
|
||||||
|
{file = "pandas-2.1.0-cp311-cp311-win_amd64.whl", hash = "sha256:d53c8c1001f6a192ff1de1efe03b31a423d0eee2e9e855e69d004308e046e694"},
|
||||||
|
{file = "pandas-2.1.0-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:86f100b3876b8c6d1a2c66207288ead435dc71041ee4aea789e55ef0e06408cb"},
|
||||||
|
{file = "pandas-2.1.0-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:28f330845ad21c11db51e02d8d69acc9035edfd1116926ff7245c7215db57957"},
|
||||||
|
{file = "pandas-2.1.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:b9a6ccf0963db88f9b12df6720e55f337447aea217f426a22d71f4213a3099a6"},
|
||||||
|
{file = "pandas-2.1.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:d99e678180bc59b0c9443314297bddce4ad35727a1a2656dbe585fd78710b3b9"},
|
||||||
|
{file = "pandas-2.1.0-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:b31da36d376d50a1a492efb18097b9101bdbd8b3fbb3f49006e02d4495d4c644"},
|
||||||
|
{file = "pandas-2.1.0-cp39-cp39-win_amd64.whl", hash = "sha256:0164b85937707ec7f70b34a6c3a578dbf0f50787f910f21ca3b26a7fd3363437"},
|
||||||
|
{file = "pandas-2.1.0.tar.gz", hash = "sha256:62c24c7fc59e42b775ce0679cfa7b14a5f9bfb7643cfbe708c960699e05fb918"},
|
||||||
|
]
|
||||||
|
|
||||||
|
[package.dependencies]
|
||||||
|
numpy = [
|
||||||
|
{version = ">=1.22.4", markers = "python_version < \"3.11\""},
|
||||||
|
{version = ">=1.23.2", markers = "python_version >= \"3.11\""},
|
||||||
|
]
|
||||||
|
python-dateutil = ">=2.8.2"
|
||||||
|
pytz = ">=2020.1"
|
||||||
|
tzdata = ">=2022.1"
|
||||||
|
|
||||||
|
[package.extras]
|
||||||
|
all = ["PyQt5 (>=5.15.6)", "SQLAlchemy (>=1.4.36)", "beautifulsoup4 (>=4.11.1)", "bottleneck (>=1.3.4)", "dataframe-api-compat (>=0.1.7)", "fastparquet (>=0.8.1)", "fsspec (>=2022.05.0)", "gcsfs (>=2022.05.0)", "html5lib (>=1.1)", "hypothesis (>=6.46.1)", "jinja2 (>=3.1.2)", "lxml (>=4.8.0)", "matplotlib (>=3.6.1)", "numba (>=0.55.2)", "numexpr (>=2.8.0)", "odfpy (>=1.4.1)", "openpyxl (>=3.0.10)", "pandas-gbq (>=0.17.5)", "psycopg2 (>=2.9.3)", "pyarrow (>=7.0.0)", "pymysql (>=1.0.2)", "pyreadstat (>=1.1.5)", "pytest (>=7.3.2)", "pytest-asyncio (>=0.17.0)", "pytest-xdist (>=2.2.0)", "pyxlsb (>=1.0.9)", "qtpy (>=2.2.0)", "s3fs (>=2022.05.0)", "scipy (>=1.8.1)", "tables (>=3.7.0)", "tabulate (>=0.8.10)", "xarray (>=2022.03.0)", "xlrd (>=2.0.1)", "xlsxwriter (>=3.0.3)", "zstandard (>=0.17.0)"]
|
||||||
|
aws = ["s3fs (>=2022.05.0)"]
|
||||||
|
clipboard = ["PyQt5 (>=5.15.6)", "qtpy (>=2.2.0)"]
|
||||||
|
compression = ["zstandard (>=0.17.0)"]
|
||||||
|
computation = ["scipy (>=1.8.1)", "xarray (>=2022.03.0)"]
|
||||||
|
consortium-standard = ["dataframe-api-compat (>=0.1.7)"]
|
||||||
|
excel = ["odfpy (>=1.4.1)", "openpyxl (>=3.0.10)", "pyxlsb (>=1.0.9)", "xlrd (>=2.0.1)", "xlsxwriter (>=3.0.3)"]
|
||||||
|
feather = ["pyarrow (>=7.0.0)"]
|
||||||
|
fss = ["fsspec (>=2022.05.0)"]
|
||||||
|
gcp = ["gcsfs (>=2022.05.0)", "pandas-gbq (>=0.17.5)"]
|
||||||
|
hdf5 = ["tables (>=3.7.0)"]
|
||||||
|
html = ["beautifulsoup4 (>=4.11.1)", "html5lib (>=1.1)", "lxml (>=4.8.0)"]
|
||||||
|
mysql = ["SQLAlchemy (>=1.4.36)", "pymysql (>=1.0.2)"]
|
||||||
|
output-formatting = ["jinja2 (>=3.1.2)", "tabulate (>=0.8.10)"]
|
||||||
|
parquet = ["pyarrow (>=7.0.0)"]
|
||||||
|
performance = ["bottleneck (>=1.3.4)", "numba (>=0.55.2)", "numexpr (>=2.8.0)"]
|
||||||
|
plot = ["matplotlib (>=3.6.1)"]
|
||||||
|
postgresql = ["SQLAlchemy (>=1.4.36)", "psycopg2 (>=2.9.3)"]
|
||||||
|
spss = ["pyreadstat (>=1.1.5)"]
|
||||||
|
sql-other = ["SQLAlchemy (>=1.4.36)"]
|
||||||
|
test = ["hypothesis (>=6.46.1)", "pytest (>=7.3.2)", "pytest-asyncio (>=0.17.0)", "pytest-xdist (>=2.2.0)"]
|
||||||
|
xml = ["lxml (>=4.8.0)"]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "pluggy"
|
name = "pluggy"
|
||||||
version = "1.3.0"
|
version = "1.3.0"
|
||||||
@@ -190,6 +351,31 @@ tomli = {version = ">=1.0.0", markers = "python_version < \"3.11\""}
|
|||||||
[package.extras]
|
[package.extras]
|
||||||
testing = ["argcomplete", "attrs (>=19.2.0)", "hypothesis (>=3.56)", "mock", "nose", "pygments (>=2.7.2)", "requests", "setuptools", "xmlschema"]
|
testing = ["argcomplete", "attrs (>=19.2.0)", "hypothesis (>=3.56)", "mock", "nose", "pygments (>=2.7.2)", "requests", "setuptools", "xmlschema"]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "python-dateutil"
|
||||||
|
version = "2.8.2"
|
||||||
|
description = "Extensions to the standard Python datetime module"
|
||||||
|
optional = false
|
||||||
|
python-versions = "!=3.0.*,!=3.1.*,!=3.2.*,>=2.7"
|
||||||
|
files = [
|
||||||
|
{file = "python-dateutil-2.8.2.tar.gz", hash = "sha256:0123cacc1627ae19ddf3c27a5de5bd67ee4586fbdd6440d9748f8abb483d3e86"},
|
||||||
|
{file = "python_dateutil-2.8.2-py2.py3-none-any.whl", hash = "sha256:961d03dc3453ebbc59dbdea9e4e11c5651520a876d0f4db161e8674aae935da9"},
|
||||||
|
]
|
||||||
|
|
||||||
|
[package.dependencies]
|
||||||
|
six = ">=1.5"
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "pytz"
|
||||||
|
version = "2023.3.post1"
|
||||||
|
description = "World timezone definitions, modern and historical"
|
||||||
|
optional = false
|
||||||
|
python-versions = "*"
|
||||||
|
files = [
|
||||||
|
{file = "pytz-2023.3.post1-py2.py3-none-any.whl", hash = "sha256:ce42d816b81b68506614c11e8937d3aa9e41007ceb50bfdcb0749b921bf646c7"},
|
||||||
|
{file = "pytz-2023.3.post1.tar.gz", hash = "sha256:7b4fddbeb94a1eba4b557da24f19fdf9db575192544270a9101d8509f9f43d7b"},
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "requests"
|
name = "requests"
|
||||||
version = "2.31.0"
|
version = "2.31.0"
|
||||||
@@ -211,6 +397,17 @@ urllib3 = ">=1.21.1,<3"
|
|||||||
socks = ["PySocks (>=1.5.6,!=1.5.7)"]
|
socks = ["PySocks (>=1.5.6,!=1.5.7)"]
|
||||||
use-chardet-on-py3 = ["chardet (>=3.0.2,<6)"]
|
use-chardet-on-py3 = ["chardet (>=3.0.2,<6)"]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "six"
|
||||||
|
version = "1.16.0"
|
||||||
|
description = "Python 2 and 3 compatibility utilities"
|
||||||
|
optional = false
|
||||||
|
python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*"
|
||||||
|
files = [
|
||||||
|
{file = "six-1.16.0-py2.py3-none-any.whl", hash = "sha256:8abb2f1d86890a2dfb989f9a77cfcfd3e47c2a354b01111771326f8aa26e0254"},
|
||||||
|
{file = "six-1.16.0.tar.gz", hash = "sha256:1e61c37477a1626458e36f7b1d82aa5c9b094fa4802892072e49de9c60c4c926"},
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "tomli"
|
name = "tomli"
|
||||||
version = "2.0.1"
|
version = "2.0.1"
|
||||||
@@ -222,6 +419,17 @@ files = [
|
|||||||
{file = "tomli-2.0.1.tar.gz", hash = "sha256:de526c12914f0c550d15924c62d72abc48d6fe7364aa87328337a31007fe8a4f"},
|
{file = "tomli-2.0.1.tar.gz", hash = "sha256:de526c12914f0c550d15924c62d72abc48d6fe7364aa87328337a31007fe8a4f"},
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "tzdata"
|
||||||
|
version = "2023.3"
|
||||||
|
description = "Provider of IANA time zone data"
|
||||||
|
optional = false
|
||||||
|
python-versions = ">=2"
|
||||||
|
files = [
|
||||||
|
{file = "tzdata-2023.3-py2.py3-none-any.whl", hash = "sha256:7e65763eef3120314099b6939b5546db7adce1e7d6f2e179e3df563c70511eda"},
|
||||||
|
{file = "tzdata-2023.3.tar.gz", hash = "sha256:11ef1e08e54acb0d4f95bdb1be05da659673de4acbd21bf9c69e94cc5e907a3a"},
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "urllib3"
|
name = "urllib3"
|
||||||
version = "2.0.4"
|
version = "2.0.4"
|
||||||
@@ -242,4 +450,4 @@ zstd = ["zstandard (>=0.18.0)"]
|
|||||||
[metadata]
|
[metadata]
|
||||||
lock-version = "2.0"
|
lock-version = "2.0"
|
||||||
python-versions = "^3.10"
|
python-versions = "^3.10"
|
||||||
content-hash = "bc3567f9501f9e18bf9f53d8b4efe1e7e3fc2d750ceda2fbab165bfa22d49c64"
|
content-hash = "3647d568f5623dd762f19029230626a62e68309fa2ef8be49a36382c19264a5f"
|
||||||
|
|||||||
@@ -1,14 +1,19 @@
|
|||||||
[tool.poetry]
|
[tool.poetry]
|
||||||
name = "homeharvest"
|
name = "homeharvest"
|
||||||
version = "0.1.2"
|
version = "0.2.3"
|
||||||
description = "Real estate scraping library"
|
description = "Real estate scraping library supporting Zillow, Realtor.com & Redfin."
|
||||||
authors = ["Zachary Hampton <zachary@zacharysproducts.com>", "Cullen Watson <cullen@cullen.ai>"]
|
authors = ["Zachary Hampton <zachary@zacharysproducts.com>", "Cullen Watson <cullen@cullen.ai>"]
|
||||||
homepage = "https://github.com/ZacharyHampton/HomeHarvest"
|
homepage = "https://github.com/ZacharyHampton/HomeHarvest"
|
||||||
readme = "README.md"
|
readme = "README.md"
|
||||||
|
|
||||||
|
[tool.poetry.scripts]
|
||||||
|
homeharvest = "homeharvest.cli:main"
|
||||||
|
|
||||||
[tool.poetry.dependencies]
|
[tool.poetry.dependencies]
|
||||||
python = "^3.10"
|
python = "^3.10"
|
||||||
requests = "^2.31.0"
|
requests = "^2.31.0"
|
||||||
|
pandas = "^2.1.0"
|
||||||
|
openpyxl = "^3.1.2"
|
||||||
|
|
||||||
|
|
||||||
[tool.poetry.group.dev.dependencies]
|
[tool.poetry.group.dev.dependencies]
|
||||||
|
|||||||
@@ -1,9 +1,40 @@
|
|||||||
from homeharvest import scrape_property
|
from homeharvest import scrape_property
|
||||||
|
from homeharvest.exceptions import (
|
||||||
|
InvalidSite,
|
||||||
|
InvalidListingType,
|
||||||
|
NoResultsFound,
|
||||||
|
GeoCoordsNotFound,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
def test_realtor():
|
def test_realtor():
|
||||||
results = [
|
results = [
|
||||||
|
scrape_property(
|
||||||
|
location="2530 Al Lipscomb Way",
|
||||||
|
site_name="realtor.com",
|
||||||
|
listing_type="for_sale",
|
||||||
|
),
|
||||||
|
scrape_property(
|
||||||
|
location="Phoenix, AZ", site_name=["realtor.com"], listing_type="for_rent"
|
||||||
|
), #: does not support "city, state, USA" format
|
||||||
|
scrape_property(
|
||||||
|
location="Dallas, TX", site_name="realtor.com", listing_type="sold"
|
||||||
|
), #: does not support "city, state, USA" format
|
||||||
scrape_property(location="85281", site_name="realtor.com"),
|
scrape_property(location="85281", site_name="realtor.com"),
|
||||||
]
|
]
|
||||||
|
|
||||||
assert all([result is not None for result in results])
|
assert all([result is not None for result in results])
|
||||||
|
|
||||||
|
bad_results = []
|
||||||
|
try:
|
||||||
|
bad_results += [
|
||||||
|
scrape_property(
|
||||||
|
location="abceefg ju098ot498hh9",
|
||||||
|
site_name="realtor.com",
|
||||||
|
listing_type="for_sale",
|
||||||
|
)
|
||||||
|
]
|
||||||
|
except (InvalidSite, InvalidListingType, NoResultsFound, GeoCoordsNotFound):
|
||||||
|
assert True
|
||||||
|
|
||||||
|
assert all([result is None for result in bad_results])
|
||||||
|
|||||||
@@ -1,12 +1,38 @@
|
|||||||
from homeharvest import scrape_property
|
from homeharvest import scrape_property
|
||||||
|
from homeharvest.exceptions import (
|
||||||
|
InvalidSite,
|
||||||
|
InvalidListingType,
|
||||||
|
NoResultsFound,
|
||||||
|
GeoCoordsNotFound,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
def test_redfin():
|
def test_redfin():
|
||||||
results = [
|
results = [
|
||||||
scrape_property(location="2530 Al Lipscomb Way", site_name="redfin"),
|
scrape_property(
|
||||||
scrape_property(location="Phoenix, AZ, USA", site_name="redfin"),
|
location="2530 Al Lipscomb Way", site_name="redfin", listing_type="for_sale"
|
||||||
scrape_property(location="Dallas, TX, USA", site_name="redfin"),
|
),
|
||||||
|
scrape_property(
|
||||||
|
location="Phoenix, AZ, USA", site_name=["redfin"], listing_type="for_rent"
|
||||||
|
),
|
||||||
|
scrape_property(
|
||||||
|
location="Dallas, TX, USA", site_name="redfin", listing_type="sold"
|
||||||
|
),
|
||||||
scrape_property(location="85281", site_name="redfin"),
|
scrape_property(location="85281", site_name="redfin"),
|
||||||
]
|
]
|
||||||
|
|
||||||
assert all([result is not None for result in results])
|
assert all([result is not None for result in results])
|
||||||
|
|
||||||
|
bad_results = []
|
||||||
|
try:
|
||||||
|
bad_results += [
|
||||||
|
scrape_property(
|
||||||
|
location="abceefg ju098ot498hh9",
|
||||||
|
site_name="redfin",
|
||||||
|
listing_type="for_sale",
|
||||||
|
)
|
||||||
|
]
|
||||||
|
except (InvalidSite, InvalidListingType, NoResultsFound, GeoCoordsNotFound):
|
||||||
|
assert True
|
||||||
|
|
||||||
|
assert all([result is None for result in bad_results])
|
||||||
|
|||||||
@@ -1,12 +1,38 @@
|
|||||||
from homeharvest import scrape_property
|
from homeharvest import scrape_property
|
||||||
|
from homeharvest.exceptions import (
|
||||||
|
InvalidSite,
|
||||||
|
InvalidListingType,
|
||||||
|
NoResultsFound,
|
||||||
|
GeoCoordsNotFound,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
def test_zillow():
|
def test_zillow():
|
||||||
results = [
|
results = [
|
||||||
scrape_property(location="2530 Al Lipscomb Way", site_name="zillow"),
|
scrape_property(
|
||||||
scrape_property(location="Phoenix, AZ, USA", site_name="zillow"),
|
location="2530 Al Lipscomb Way", site_name="zillow", listing_type="for_sale"
|
||||||
scrape_property(location="Dallas, TX, USA", site_name="zillow"),
|
),
|
||||||
|
scrape_property(
|
||||||
|
location="Phoenix, AZ, USA", site_name=["zillow"], listing_type="for_rent"
|
||||||
|
),
|
||||||
|
scrape_property(
|
||||||
|
location="Dallas, TX, USA", site_name="zillow", listing_type="sold"
|
||||||
|
),
|
||||||
scrape_property(location="85281", site_name="zillow"),
|
scrape_property(location="85281", site_name="zillow"),
|
||||||
]
|
]
|
||||||
|
|
||||||
assert all([result is not None for result in results])
|
assert all([result is not None for result in results])
|
||||||
|
|
||||||
|
bad_results = []
|
||||||
|
try:
|
||||||
|
bad_results += [
|
||||||
|
scrape_property(
|
||||||
|
location="abceefg ju098ot498hh9",
|
||||||
|
site_name="zillow",
|
||||||
|
listing_type="for_sale",
|
||||||
|
)
|
||||||
|
]
|
||||||
|
except (InvalidSite, InvalidListingType, NoResultsFound, GeoCoordsNotFound):
|
||||||
|
assert True
|
||||||
|
|
||||||
|
assert all([result is None for result in bad_results])
|
||||||
|
|||||||
Reference in New Issue
Block a user